
AI 및 딥러닝에 대한 구현 자료를 인터넷에서 검색해보면 대부분 파이썬을 사용하고 있죠.
반면 통계 계산에 대한 자료를 검색해보면 요즘에는 파이썬도 많이 늘었지만 R이 차지하는 비중이 높습니다.
딥러닝을 제대로 연구하고 활용하기 위해서는 딥러닝에 대한 이해만이 아니라 데이터 분석과 통계에 대한 이해도 중요하다고 하는데 R과 파이썬으로 나누어져 있으니 약간 귀찮습니다.
그래서 R과 Python을 사용한 통계계산 시리즈를 통해 두 가지 개발환경 모두를 연습해 보고자 합니다.
* R 개발환경: RStudio
* 파이썬 개발환경: Python 3.7, Anaconda, Jupyter Notebook
(IDE 등의 버전은 각자 편한 것으로 사용하시면 됩니다.)
일단 기준이 되는 도서는 "기반지식/통계" 카테고리에서 다루고 있는 "데이터 과학을 위한 통계"를 선택하도록 하겠습니다.
물론 선택 도서만 다루지 않고 관련된 내용들은 계속 보충해 나갈 계획입니다.
연습해 보는 코드는 선택 도서의 코드를 기반으로 하겠지만.. 아무래도 판매되고 있는 도서 내용을 그대로 사용하는 것은 저자나 출판사에 미안한 일이기때문에 가장 기초적인 일부는 도서를 활용하고 나머지는 따로 문제를 만들거나 또는 검색하거나 해서 다루려고 합니다.
그리고 "데이터 과학을 위한 통계"에서는 R만 사용하고 있는데 동일한 계산을 파이썬으로도 구현해서 다룰 예정입니다.
먼저 제일 기준이 되는 데이터 받기를 한 번 해 보겠습니다.
데이터는 깃허브 https://github.com/andrewgbruce/statistics-for-data-scientists 에서 다운로드 가능합니다.
깃허브를 통해서 데이터를 다운로드 받으려고 하면 포함된 소스코드 중에서 download_data.r 파일을 실행하면 됩니다.
제일 처음 시작하는 예제를 위해서는 state.csv 파일을 다운로드하여 사용할텐데, R을 처음 사용하는 분들은 제일 처음 시작 줄부터 오류가 날 것입니다.
해당 코드는 다음과 같습니다. (제가 사용하고 있는 코드블럭 설정에는 R 언어가 없군요.. ㅠㅠ)
library(googledrive)
PSDS_PATH <- file.path('~', 'statistics-for-data-scientists')
## Import state data
drive_download(as_id("0B98qpkK5EJembFc5RmVKVVJPdGc"), path=file.path(PSDS_PATH, 'data', 'state.csv'), overwrite=TRUE)첫 줄의 library(googledrive)라는 부분은 googledrive 라이브러리를 사용하겠다는 뜻인데 처음 R을 사용하는 분의 환경에는 해당 라이브러리가 설치되어 있지 않을 것입니다.
그럼 설치를 해 주어야 하겠죠.
install.packages("googledrive")
library(googledrive)
PSDS_PATH <- file.path('~', 'workspace/statistics-for-data-scientists')
drive_download(as_id("0B98qpkK5EJembFc5RmVKVVJPdGc"), path=file.path(PSDS_PATH, 'data', 'state.csv'), overwrite=TRUE)
위의 코드에서 보듯이 install.packages("googledrive") 라는 코드로 라이브러리의 설치가 가능합니다.
가끔 지정한 경로가 맞지 않거나 폴더를 생성할 권한이 없어서 실패하는 경우가 있는데, 이런 경우에는 올바른 경로를 지정하거나 파일을 다운로드 받고자 하는 폴더를 미리 생성해 두고 해당 경로를 지정하면 됩니다.
위와 같이 코드를 수정해서 실행해 보면 아래와 같은 결과를 얻을 수 있습니다.
이제 설정한 폴더를 보시면 state.csv 파일을 찾을 수 있을 것입니다.
state.csv 파일을 열어보면 아래와 같은 내용으로 구성되어 있습니다.
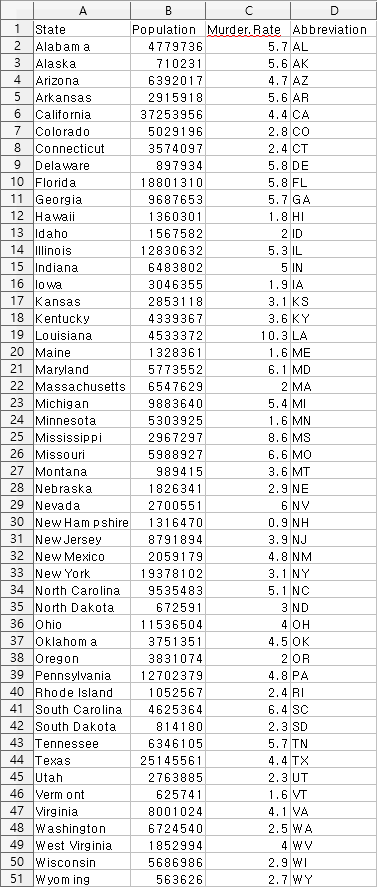
흠.. 처음 시작부터 데이터의 내용이 인구 대비 살인사건 발생비율이군요. -_-;;
첫번째 줄은 데이터의 분류명이 기록된 헤더입니다.
실제 데이터는 50개가 되겠군요.
그럼 이제 이 데이터 파일을 R에서 사용하기 위하여 읽어들여야 합니다.
csv 파일을 읽고 기본적인 평균, 중간값을 계산해 보도록 하겠습니다.
data_path <- file.path('~', 'workspace/statistics-for-data-scientists/data/state.csv')
state <- read.csv(file=data_path)
state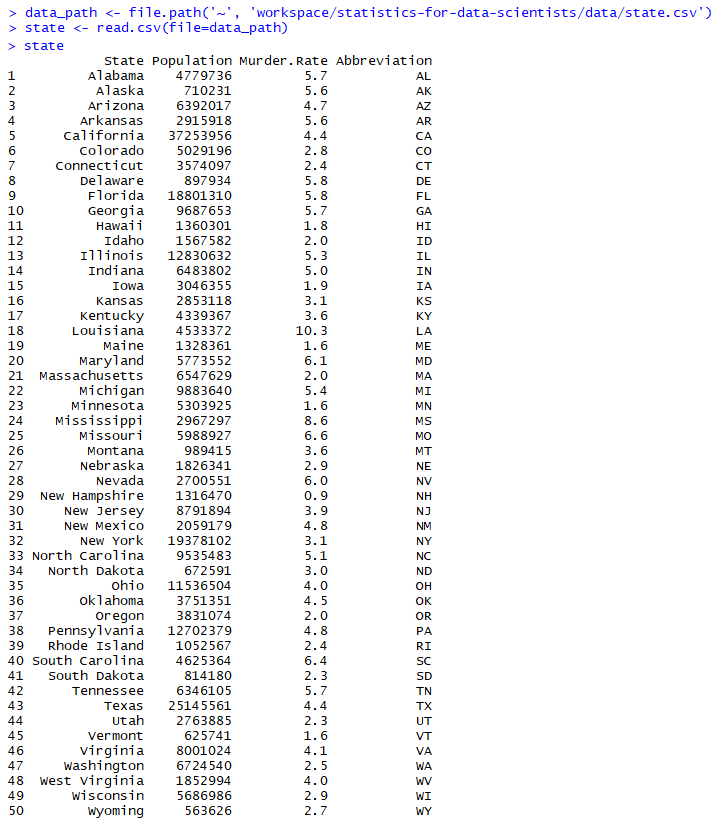
mean(state[["Population"]]) # 평균
median(state[["Population"]]) # 중간값
잘 계산되었군요.
그렇다면 이제 파이썬으로 동일한 작업을 해 보겠습니다.
파이썬에서는 다양하게 csv 파일을 읽을 수 있습니다. (R도 마찬가지입니다만..)
그냥 파일로 읽어서 처리하거나, numpy 또는 pandas와 같은 라이브러리를 통해서 읽을 수 있습니다.
그런데 일반 파일로 csv파일을 읽어서 사용하는건 좀 불편하기도 하고, 어차피 라이브러리가 지원해주는 기능때문에 통계든 데이터 분석이든 사용하려면 대부분 numpy 또는 pandas를 쓰게 됩니다.
글 초반에서 말씀드렸던 사용하는 개발환경을 보시면 Anaconda를 사용한다고 되어있는데 Anaconda는 미리 많은 라이브러리를 설치해 둔 환경이라서 사용이 편리하다는 장점이 있습니다.
꼭 Anaconda가 아니라 다른 환경을 사용하셔도 무방합니다.
이번 글에서는 pandas를 사용해 보겠습니다.
numpy는 숫자 데이터를 처리하는 것을 목적으로 하고 있는데 우리가 사용할 데이터는 숫자, 문자열이 함께 사용되고 있기때문에 편리하게 pandas만 사용해 봅니다.
먼저 csv 파일을 읽은 후, R과 마찬가지로 평균, 중간값을 계산해 보도록 하겠습니다.
import pandas as pd
csv_data = pd.read_csv('./data/state.csv')
csv_data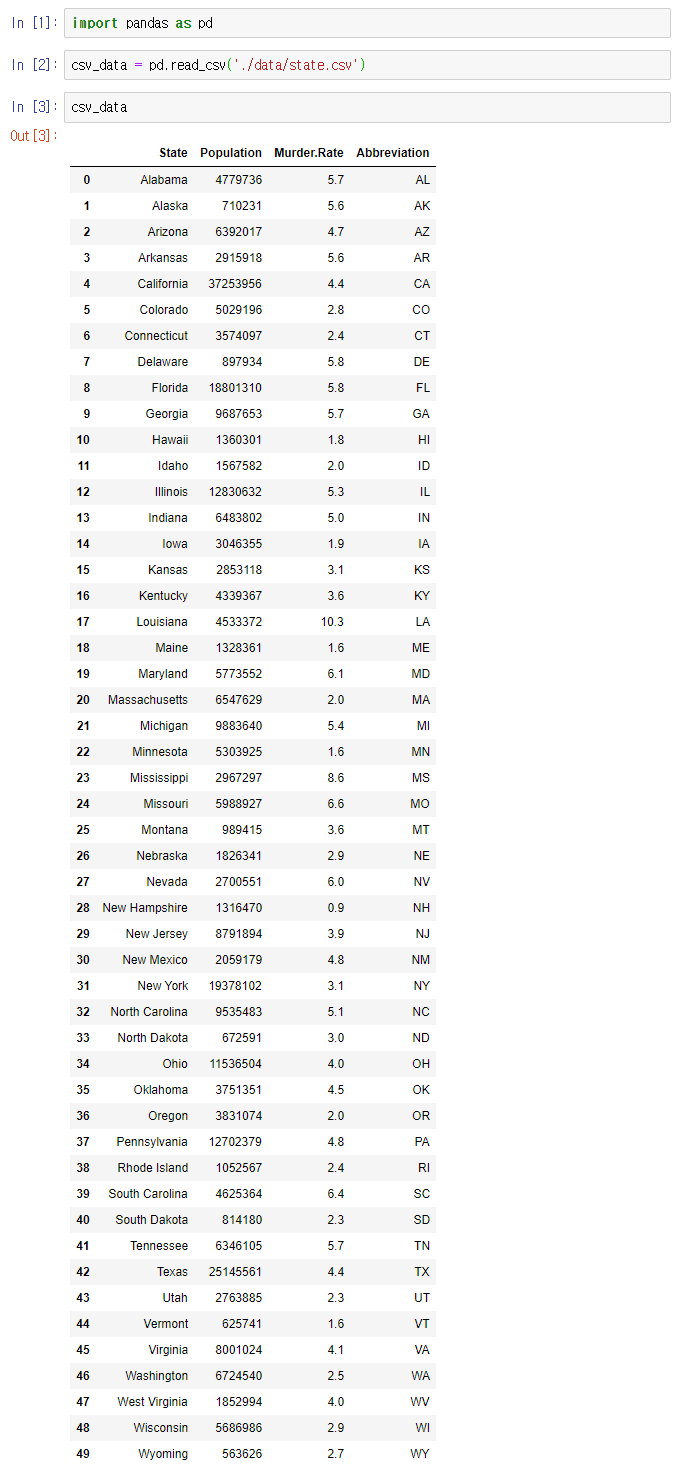
이것저것 신경쓰지 않아도 그냥 깔끔하게 나오는군요.
pasnda는 read_csv라고 csv 파일을 읽기 위한 메소드가 이미 존재하기때문에 편리하게 사용할 수 있습니다.
여러가지 옵션을 설정하여 더 확장성있게 사용할 수도 있지만 그냥 파일명만 주고 읽어도 문제 없습니다.
R과 마찬가지로 평균과 중간값을 계산해 보기로 하죠.
csv_data.mean() # 숫자로 된 모든 컬럼의 평균
csv_data['Population'].mean() # Population 컬럼의 평균
csv_data.median() # 숫자로 된 모든 컬럼의 중간값
csv_data['Population'].median() # Population 컬럼의 중간값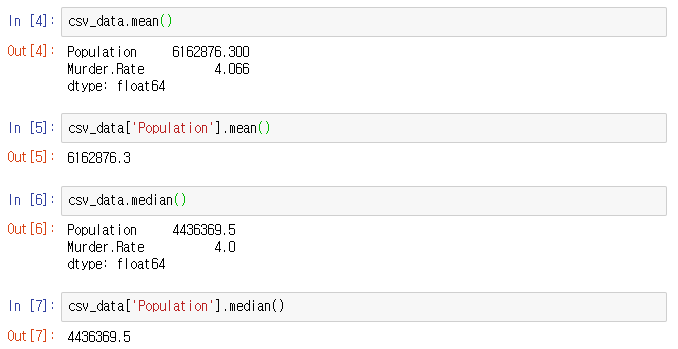
역시 간단하게 처리가 되었습니다.
이번 글에서는 R과 파이썬을 이용하여 데이터 파일(csv)을 읽고 간단한 통계 계산을 실행해 보았습니다.
다음 글부터는 하나씩 통계 계산 주제를 잡아서 진행하도록 하겠습니다.
'AI 기반 이론' 카테고리의 다른 글
| 데이터 분석의 힘: 6~7장 (0) | 2020.01.04 |
|---|---|
| 데이터 분석의 힘: 5장 (2) | 2019.12.26 |
| 데이터 분석의 힘: 4장 (2) | 2019.12.16 |
| 데이터 분석의 힘: 3장 (0) | 2019.12.10 |
| 데이터 분석의 힘: 1~2장 (2) | 2019.12.06 |