
이번 글에서는 시간의 흐름에 따른 패널 데이터 분석에 대하여 이야기 하겠습니다.
먼저 패널 데이터란 무엇일까요?
패널 데이터란 복수의 집단에 대하여 복수의 기간에 걸쳐 수집한 데이터를 말합니다.
예를 들면 지역별 부동산 데이터를 다년간 관측하는 것 등을 들 수 있습니다.
패널 데이터 분석은 RCT가 불가능할 때 사용할 수 있는 자연실험 기법 중 하나입니다.
기존에 존재하는 데이터의 흐름을 변화시킬 수 있는 어떤 조건이 주어졌을때, 해당 조건의 실행에 영향을 받은 집단과 영향을 받지 않은 집단이 있다면 RCT처럼 실험을 하지 않더라도 개입집단과 비교집단이 저절로 만들어질 수 있는데, 이 경우 개입 전후의 두 집단의 데이터가 있다면 설득력이 높은 인과관계의 분석이 가능할 것입니다.
이런 생각으로 데이터를 분석해 나가는 것을 패널 데이터 분석이라고 합니다.
아래의 그림은 덴마크에서 납세 데이터를 기준으로 수집한 1987년~1994년 사이의 이민자 수의 추이를 보여주는 그래프입니다.
1991년의 세제 개혁을 통해 연간소득이 일정 금액 이상인 외국인 노동자의 소득세 감세에 따른 영향을 볼 수 있는 데이터입니다.
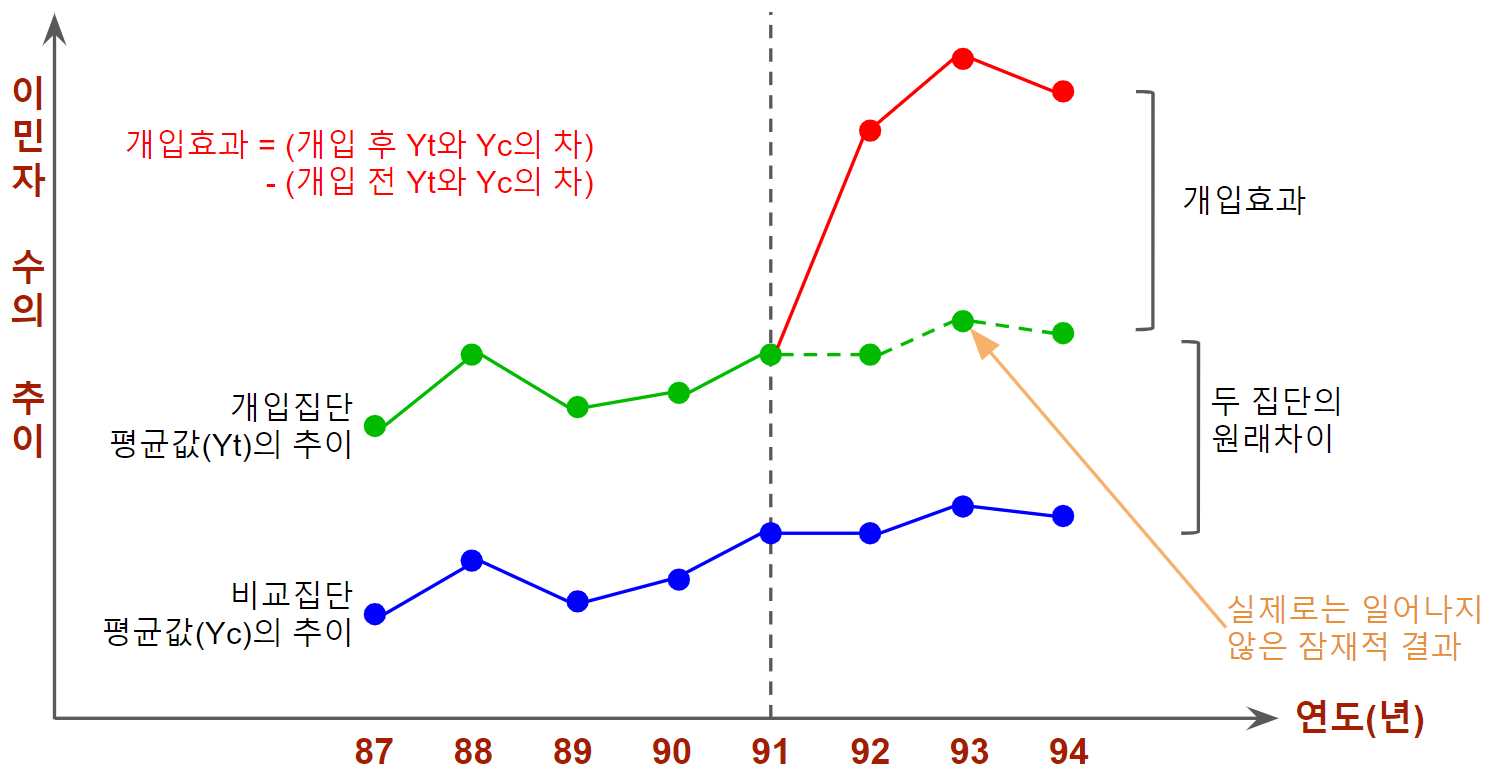
위의 그래프를 보시면 1991년 개입이 시작되면서 개입집단과 비교집단의 차이가 명확하게 드러나는 것을 확인할 수 있습니다.
두 집단은 1991년 이전에는 같은 움직임을 보이지만 1991년 이후에는 상당히 다른 움직임을 보이고 있죠.
이런 차이를 근거로 하여 1991년의 세제개혁(X)이 이민자 수(Y)에 영향을 주었다는 인과관계를 주장할 수 있다는 것이 패널 데이터 분석의 기본적인 사고방식이자 핵심 내용입니다.
두 집단에 대한 개입효과는 각 집단에서 개입 전의 특정시점의 값과 개입 후의 특점시점의 값에 대한 차이를 계산함으로써 확인 가능합니다.
이렇게 두 개 이상의 집단에서 동일한 특정 시점 사이의 차이를 이용한다고 해서 패널 데이터 분석 방법은 이중차분법(Difference in Differences Method)이라고도 부릅니다.
앞에서 살펴본 RCT, RD디자인, 집군분석과 마찬가지로 패널 데이터 분석에서도 가정을 필요로 합니다.
패널 데이터 분석에서 사용하는 가정은 평행 트렌드 가정(Parallel Trend Assumption)인데 평행 트렌드 가정이란
- 만약 개입이 일어나지 않았다면 개입집단의 평균값(Yt)과 비교집단의 평균값(Yc)은 평행한 추이를 보인다.
라는 것입니다.
두 집단이 개입이 없을때에도 평행한 모습을 보이지 않았다면 개입 후의 값이 개입의 영향인지 아닌지를 추론할 근거가 없어지겠죠.
개입 전의 값이 서로 평행을 이룬다는 가정이 성립해야만 개입이라는 요소의 영향력이 입증됩니다.
따라서 분석자는 평행 트렌드 가정이 성립할 것이라는 주장을 하기 위한 작업을 수행해야 합니다.
먼저 개입 이전의 데이터를 모아 개입집단과 비교집단 사이에 평행 트렌드 가정이 성립하는지 조사하여야 하고, 다음으로 개입 이후에 개입집단에만 영향을 미친 또 다른 사건이나 변수가 없었는지 확인해야 합니다.
또다른 원인이 될 수 있는 사건, 변수가 있다면 개입 조건이 현재의 결과에 대한 원인이라고 주장할 수 없을 것입니다.
다시 정리하면 패널 데이터 분석을 위한 원칙은 아래와 같습니다.
| 패널 데이터 분석의 원칙 1. 개입을 전후해서 개입집단과 비교집단 양쪽의 데이터를 입수할 수 있는지 확인한다. 2. 평행 트렌드 가정이 성립하는지 검증한다. 3. 평행 트렌드 가정이 성립할 가능성이 높다면 두 집단의 평균값 추이를 그래프로 그림으로써 개입 효과의 평균값을 측정한다. 출처: 데이터분석의 힘 (이토 고이치로 저 / 전선영 역, 인플루엔셜) 5장 Summary |
그렇다면 패널 데이터 분석이 가지는 강점과 약점은 무엇일까요?
| 패널 데이터 분석의 강점 1. 필요한 데이터만 확보된다면 RD디자인이나 집군분석 이상으로 광범위하게 이용할 수 있다. 2. 결과를 그래프로 보여줄 수 있어 쉽고 투명한 분석이 가능하다. 3. 개입집단 전체에 대한 개입 효과를 분석할 수 있다. 분석 대상이 제한된 RD디자인이나 집군분석에 비해 강점이다. 패널 데이터 분석의 약점: 1. 분석에 필요한 가정이 성립할 것이라는 근거를 제시할 수는 있지만 입증할 수는 없다. 이는 RCT와 비교했을 때 큰 약점이다. 2. RD디자인이나 집군분석에 필요한 가정에 비해 평행 트렌드 가정은 매우 까다로운 가정이며 실제로는 성립하지 않는 경우도 많다. 출처: 데이터분석의 힘 (이토 고이치로 저 / 전선영 역, 인플루엔셜) 5장 Summary |
이번 글에서는 5장의 패널 데이터 분석을 살펴보았습니다.
다음 글에서는 6~7장을 다루고 "데이터 분석의 힘"의 학습을 마무리하도록 하겠습니다.
'AI 기반 이론' 카테고리의 다른 글
| 시계열 데이터와 딥러닝 (0) | 2020.03.13 |
|---|---|
| 데이터 분석의 힘: 6~7장 (0) | 2020.01.04 |
| R과 파이썬을 사용한 통계 계산 시작하기 (1) (0) | 2019.12.19 |
| 데이터 분석의 힘: 4장 (2) | 2019.12.16 |
| 데이터 분석의 힘: 3장 (0) | 2019.12.10 |