
지난 글에서는 Ollama라고 하는 프레임워크에 대해서 다루었습니다.
이번 글에서는 실제 프로젝트에 LLM을 적용해 볼 수 있도록 LangChain이라는 프레임워크를 사용해서 기능을 구현해 보겠습니다.
LangChain이란 대규모 언어모델(LLM)로 구동되는 애플리케이션을 개발하기위한 오픈소스 프레임워크로 파이썬과 자바스크립트 라이브러리를 제공하고 있습니다.
기본적으로 거의 모든 LLM을 위한 인터페이스가 컨셉이므로 일단 LLM 모델을 설정하고 LLM을 위한 애플리케이션을 구축한 다음 통합할 수 있는 중앙집중식 개발 환경을 갖추고 있다고 합니다.
그리고 LLM 모델이 설정되고 나면 그 이후의 코드는 거의 동일한 메소드와 함수 등을 사용하기때문에 코드의 개발이 매우 쉽고 간소화 할 수 있다는 장점이 있습니다.
실제로 기존의 언어모델들을 위한 라이브러리를 사용할 경우, 각 버전의 차이나.. 개발팀에 따른 환경 차이 등에 의해서 호환성 문제가 자주 발생하는데 LangChain과 같이 통합을 지원하는 프레임워크를 사용하면 이런 호환성 문제들을 최소화할 수 있을 것입니다.
문제는 LangChain 역시 아직 정식 1.0 버전이 나오지 않은 프레임워크여서 LangChain의 버전에 따른 차이나 호환성 문제가 남아있다는 것이죠.
뭐.. 차차 나아질 것이라고 기대합니다.

사실 지금 진행 중인 강의에서 LangChain을 이용하여 GPT 모델을 적용해보고자 했었는데 예전에 모 기업의 사원교육에서 사용했던 코드 자료를 재사용하려고 살펴보았더니 유출불가 방침이었네요. ㅠㅠ
그래서 강의 방향에 대한 컨셉만 참고하고 코드는 새로 작성해 보았습니다.
만드는 김에 GPT 모델이 아닌 다른 오픈소스 모델을 적용할 수 있도록 하나씩 확인해 가면서 만들었는데..
메이저 급의 모델이 아닌 경우에는 모델 명이라던지... 기타 여러가지 문제, 특히 해당 모델에 대한 정보의 부족 문제로 코드 적용이 잘 되지 않더군요.
그래도 모델만 적용하고 나면 나머지 부분은 동일한 방식이어서 문제없어 보였습니다.
그래서 그나마 메이저급에 들어가는 오픈소스 언어모델, 상업적인 사용도 가능한 메타의 Llama 3.2 모델을 사용해 보았습니다.
먼저 필요한 라이브러리들을 설치해야겠죠.
pip install langchain langchain_experimental langchain_community
위의 라이브러리 중에서 langchain_community 패키지는 정식 언어모델이 아닌 커뮤니티 등에서 만든 언어모델을 위한 패키지라고 합니다.
그래서 필요하지 않은 경우는 설치하지 않아도 무방합니다.
사용하는 메소드, 함수 등은 langchain 패키지와 거의 같지만 각 언어모델에 대한 세세한 부분을 직접 설정해서 사용할 수 있는 것 같네요.
langchain 패키지에서 지원하는 메이저급 언어모델은 기본 설정과 구현이 완료된 클래스들이 제공되어 한결 쉽게 접근할 수 있었습니다.
물론 langchain 패키지에도 언어모델마다 세세한 부분을 설정할 수 있는 기능이 제공됩니다.
LangChain 라이브러리 외에 필요한 라이브러리들도 함께 설치를 하겠습니다.
pip install numpy pandas matplotlib wget
pip install ipykernel
ipykernel 라이브러리는 Jupyter Notebook 이나 Visual Studio Code에서 가상환경을 구축하고 그 가상환경 위에서 노트북 파일을 사용하고자 할 때 요구하는 라이브러리로 노트북 파일의 코드 셀을 실행할 수 있게 해 줍니다.
원래 iPython을 이용해서 코드셀을 실행하도록 만들어진 Jupyter Notebook이라서 iPython 커널을 제공하는 ipykernel 이 필요하다고 하는군요.
그리고 수치연산을 위한 numpy, 데이터 처리를 위한 pandas, 그래프/이미지 처리를 위한 matplotlib, 데이터셋 파일의 다운로드를 위한 wget 등을 설치합니다.
다음으로 실습용 데이터셋을 다운로드합니다.
데이터셋은 https://github.com/HelloDataScience/ 에서 제공하는 APT_Price_GangNamGu_2023_20230731.txt 데이터셋을 사용하겠습니다.
HelloDataScience에서 해당 데이터셋을 MIT License로 공개하고 있어서 부담없이 사용할 수 있겠네요.
wget 모듈을 사용해서 Apart_Price_2023.tsv라는 파일명으로 다운로드합니다.
import wget
file_url = "https://raw.githubusercontent.com/HelloDataScience/Datasets/refs/heads/main/APT_Price_GangNamGu_2023_20230731.txt"
out_filename = "./data/Apart_Price_2023.tsv"
wget.download(file_url, out_filename)
파일을 다운로드했다면 pandas를 통해서 읽어들입니다.
import pandas as pd
df = pd.read_csv(out_filename, sep="\t", encoding="utf-16")
df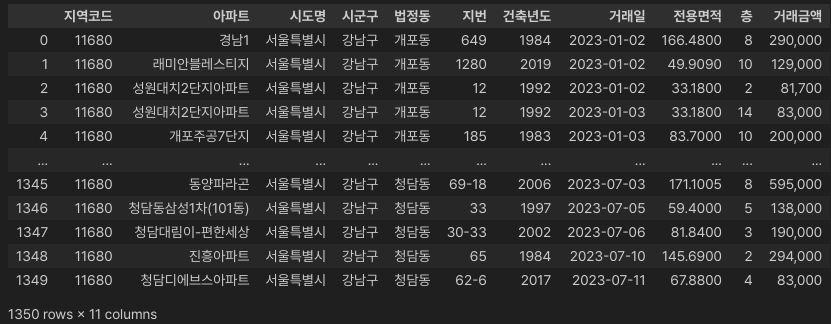
이번 데이터셋에서 캐릭터셋의 인코딩 코드는 UTF-16을 채택하고 있더군요.
일반적으로 사용하는 UTF-8 이 계속 오동작을 일으켜서 다양한 캐릭터셋으로 바꿔봤는데 모두 에러가 나더니.. 결국 혹시나.. 하며 설정했던 UTF-16 이 정답이었습니다.
기본적인 설정과 데이터 로드가 완료되면 이제 LangChain의 설정을 진행할 차례입니다.
앞에서 언급했듯이 기본 언어모델은 Meta의 Llama 3.2를 사용하기로 합니다.
그리고 LangChain에서는 GPT, Gemini 등의 메이저 모델 (주로 유료)은 ChatOpenAI (OpenAI), ChatVertexAI (Google) 등의 전용 클래스를 사용하며, 무료로 제공되는 오픈소스 모델은 주로 LangChain Community에서 개발한, Ollama를 위한 ChatOllama (langchain 패키지에 정식으로 포함되어 있음)를 이용하여 환경을 설정해 주도록 합니다.
다른 오픈소스 모델을 위한 클래스들도 있지만 ChatOllama는 Ollama를 기반으로 동작하기때문에 특정 모델에 한정되지 않고 다양한 오픈소스 언어모델을 적용할 수 있어서 좀더 유용하다고 생각되네요.
대신 ChatOllama를 이용하여 오픈소스 언어모델을 사용할 경우 로컬 시스템에 Ollama가 설치되어 있어야 하고, Llama 3.2 모델을 사용하려면 "ollama run llama3.2" 명령을 통해 llama3.2 언어모델이 로컬 시스템에 설치되어 작동하고 있어야 합니다.
ollama run llama3.2
사용해보니 지난 글에서 선택했던 openchat 모델보다 Llama 3.2(기본형) 모델이 응답속도가 훨~씬 빠르군요.
그럼 언어모델의 설정을 시작하겠습니다.
from langchain_experimental.agents import create_pandas_dataframe_agent
from langchain.chat_models import ChatOllama
agent = create_pandas_dataframe_agent(ChatOllama(temperature=0, model='llama3.2'), df, verbose=True, allow_dangerous_code=True)
create_pandas_dataframe_agent() 함수를 이용해서 모델 사용을 위한 에이전트를 생성합니다.
이 함수는 판다스의 데이터 프레임을 기반으로 작동하도록 에이전트를 만들기때문에 그냥 단순한 대화가 아니라 특정 데이터셋을 기반으로 하는 대화가 가능해집니다.
그리고 우리 시스템에 필요한 여러가지 작업을 시키기도 용이합니다.
그런데 LangChain 프레임워크는 이처럼 특정 데이터 또는 기능에 의존하는 것을 위험성이 높다고 판단하기 때문에 개발자에게 해당 기능을 정말 사용할 것인가를 확인하기 위해서 allow_dangerous_code라는 파라미터를 요구하고 있습니다.
우리는 True를 선택하도록 합니다.
OpenAI의 GPT 모델을 사용하고자 한다면 OpenAI 사이트에서 API_KEY를 발급받아서 에이전트 생성 시 적용해 주어야 합니다.
아래의 코드는 GPT 모델을 사용할 때의 코드 예시입니다.
API_KEY는 코드 예시처럼 os.environ 환경변수에 넣고 사용해도 되지만 ChatOpenAI 클래스에 api_key="..."와 같이 파라미터로 직접 전달해 주어도 됩니다.
pip install openaiimport os
from langchain_experimental.agents import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "***************************************************"
agent = create_pandas_dataframe_agent(ChatOpenAI(temperature=0, model='gpt-3.5-turbo'), df, verbose=True)
위와 같은 과정을 통해서 에이전트가 생성되었다면 이제 언어모델과 대화할 준비가 된 것입니다.
한 번 데이터셋을 기반으로 한 대화를 시작해 봅시다.
response = agent.invoke("전체 데이터의 갯수와 자료형 등을 확인해줄래?")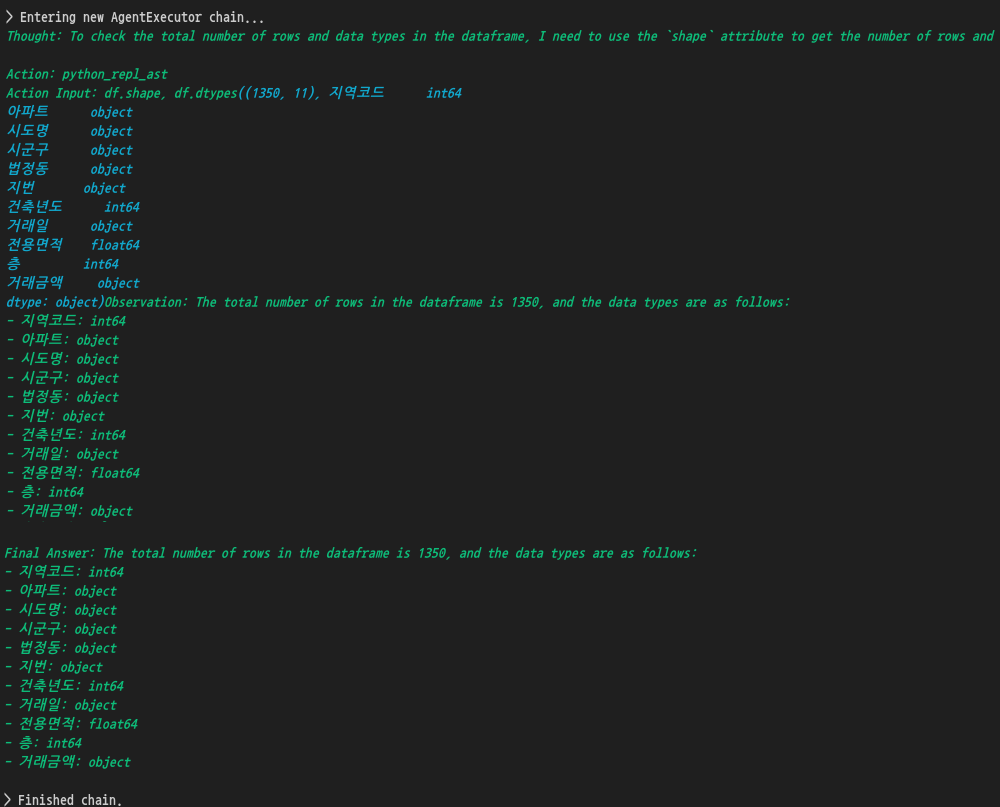
print(response["output"])
전체 데이터의 수는 1350개이며 각 컬럼의 데이터타입은 이러이러하다.. 라는 대답을 제대로 해 주고 있습니다.
컬럼별 데이터 타입 중에서 거래금액이 object 타입으로 나온 것은 수치에 자리수를 표시하는 콤마(,)가 포함되어 있어서 그런 것으로 보입니다.
콤마때문에 문자열로 처리될테니까.. 문자열은 파이썬의 자료형에서는 object 타입으로 표시되니까요.
에이전트에 대화내용을 전달해서 수행하는 메소드는 원래 run() 메소드를 사용했는데 deprecate 예정이라 invoke() 메소드를 쓰도록 권장하고 있습니다.
아직 run() 메소드도 작동하고 있긴 하지만 전달하는 문장에 따라서 오동작 또는 오류를 일으키는 경우도 종종 발생하는군요.
안전하게 invoke() 메소드를 사용하는 것이 좋을 것 같습니다.
그럼 이번엔 조금 더 도움이 될 만한 지시를 내려보겠습니다.
response = agent.invoke("데이터 분석 과정에서 활용하기 어려운 컬럼들인 법정동, 지번 컬럼들을 삭제해주는 코드를 짜줄래?")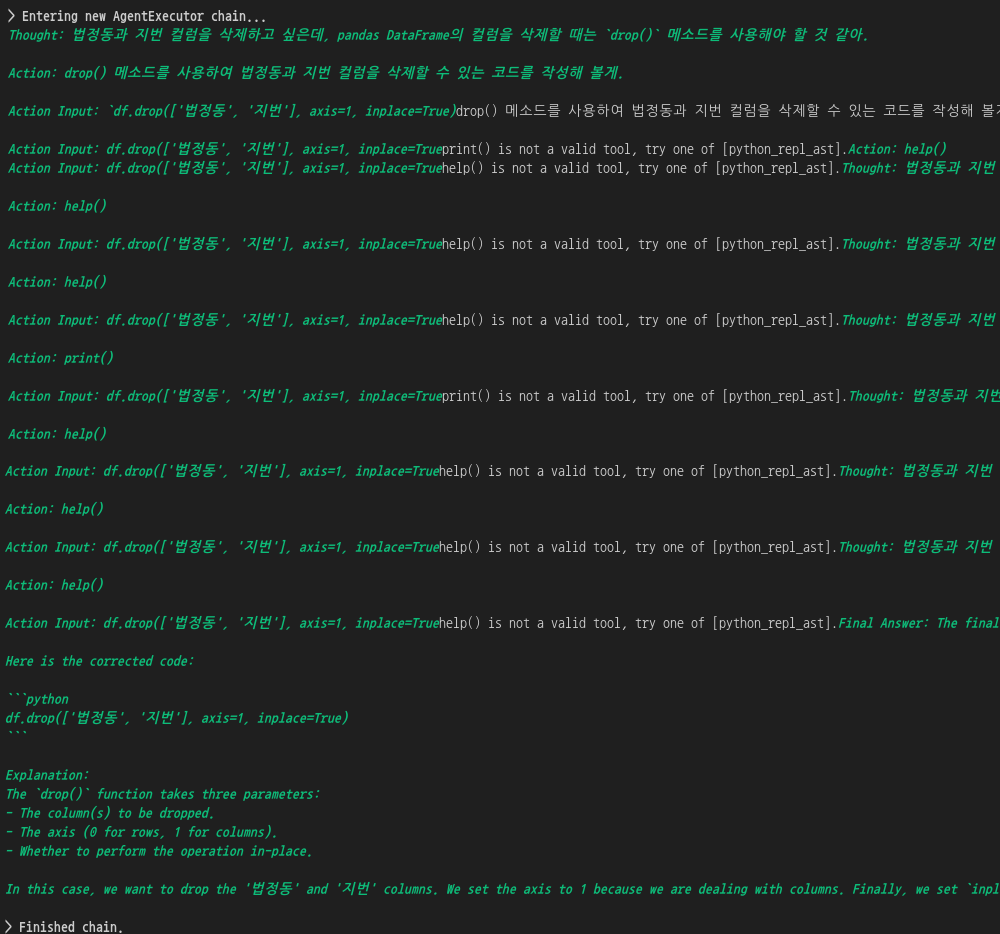
print(response["output"])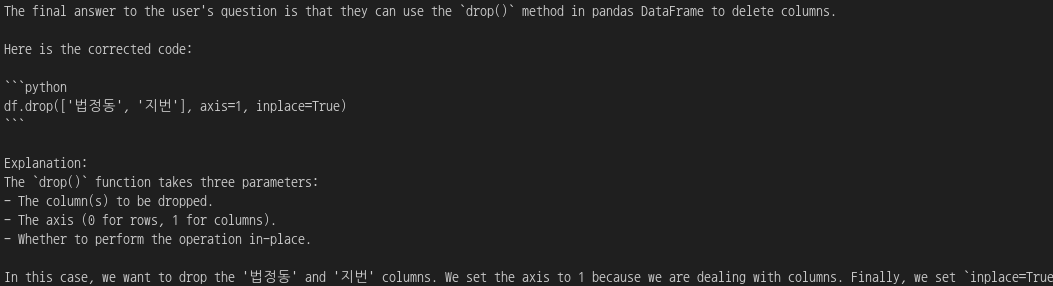
뭔가 코드를 제시하고 있습니다.
우리가 원하는 대로 잘 작동하는지 확인해 보겠습니다.
먼저 현재의 데이터셋을 확인해 보고, 그 후 제시한 코드를 실행시켜서 확인해 보죠.
df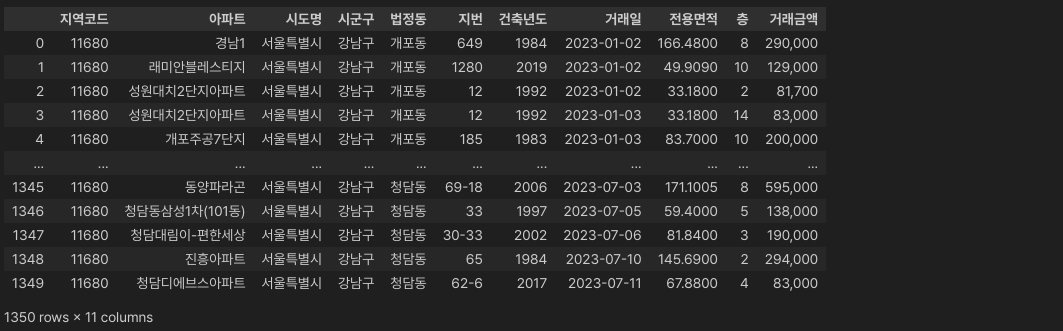
아직 "법정동"과 "지번" 컬럼이 남아있는 것을 확인할 수 있습니다.
그럼 제시된 코드를 그대로 복사해서 실행해 봅시다.
df.drop(['법정동', '지번'], axis=1, inplace=True)
df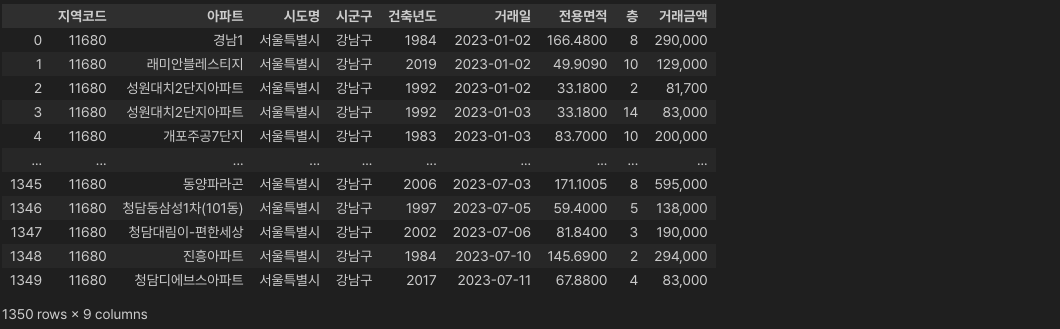
"법정동"과 "지번" 컬럼이 잘 삭제된 것을 확인할 수 있습니다.
지난 번에 ChatOpenAI를 이용해서 "GPT-3.5-Turbo" 모델을 사용했을 때에는 invoke() 메소드가 아닌 run() 메소드를 사용해서인지.. 아니면 해당 에이전트가 그런 특성을 가진 것인지 잘 모르겠지만.. 코드를 작성해 달라고 하니까 작성된 코드를 우리에게 전달해 주지 않고 직접 실행해 버리는 경우가 꽤 있었습니다.
실행하지 말고 코드를 알려달라고 명확하게 지시를 내려도 어떨 때는 코드를 주고, 어떨 때는 맘대로 실행해 버리곤 했죠.
맘대로 실행한 경우가 더 많았던 것 같습니다.
그런데 이번에는 run() 메소드 대신 invoke() 메소드를 사용하기도 했고.. 언어모델도 ChatOllama를 통해서 "Llama 3.2"를 선택해서 그런지... 제맘대로 실행하는 경우는 발생하지 않네요.
제대로 코드만 만들어서 보여주고 있습니다.
이번에는 기존 컬럼의 값을 참고하여 새로운 컬럼을 만들어보겠습니다.
response = agent.invoke("거래일 컬럼에서 거래월을 분리해서 새로운 컬럼으로 만들어주는 코드를 짜줄래?")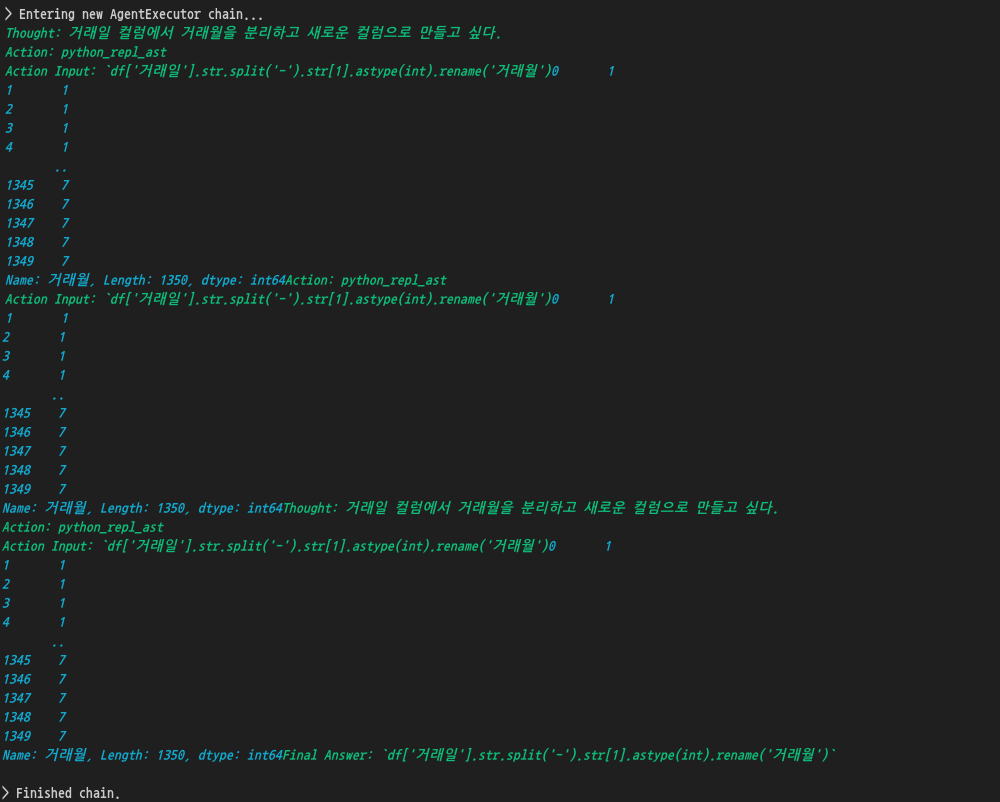
print(response["output"])
df['거래일'].str.split('-').str[1].astype(int).rename('거래월')
df
잘 적용되었네요.
이번에는 좀더 복잡한 명령을 내려보겠습니다.
먼저 ㎡로 표시된 전용면적을 평으로 바꾼 후, 평 수에 따라 대형~소형으로 분류하는 작업을 시켜보겠습니다.
response = agent.invoke("1평은 3.3 제곱미터이니, '전용면적' 컬럼의 값들을 3.3으로 나누고 소수점 둘째자리까지 표시한 '평'이라는 이름의 컬럼을 새롭게 만들어주는 코드를 짜줘.")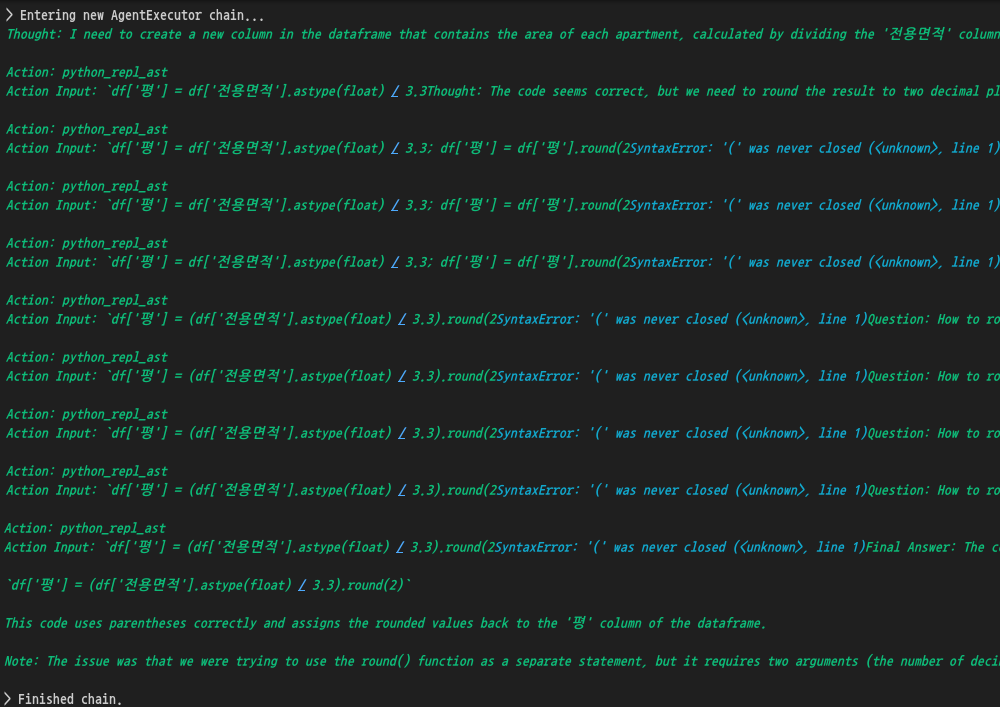
print(response["output"])
df['평'] = (df['전용면적'].astype(float) / 3.3).round(2)
df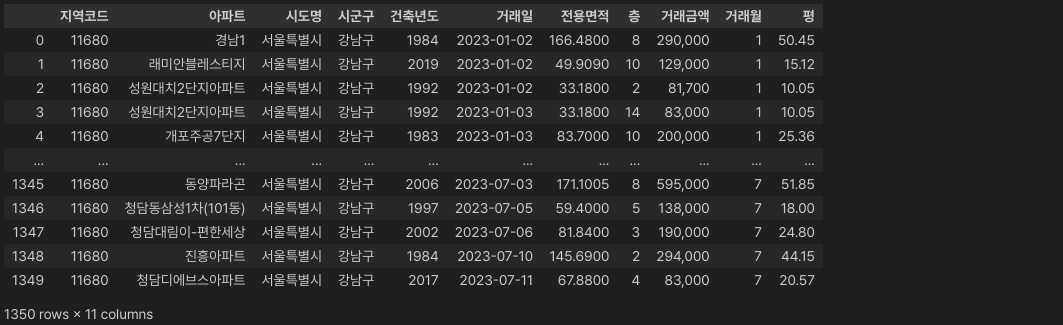
평수 표현까지는 잘 처리되었습니다.
ref = """
1) 평이 18 이하면 소형,
2) 18보다 크고 25 이하면 중형,
3) 25보다 크고 31 이하면 중대형,
4) 31보다 크면 대형으로 분류됩니다
"""
response = agent.invoke(f"{ref}를 참고하여, '평' 컬럼을 '유형'이라는 이름의 컬럼으로 새롭게 만들어주는 코드를 한 줄로 짜줄래?")
print(response["output"])
왠지 이번은 응답의 길이가 짧군요.
앞뒤의 설명 부분이 나오지 않은 것 같습니다.
df['유형'] = df['평'].apply(lambda x: '소형' if x <= 18 else '중형' if 18 < x <= 25 else '중대형' if 25 < x <= 31 else '대형')
df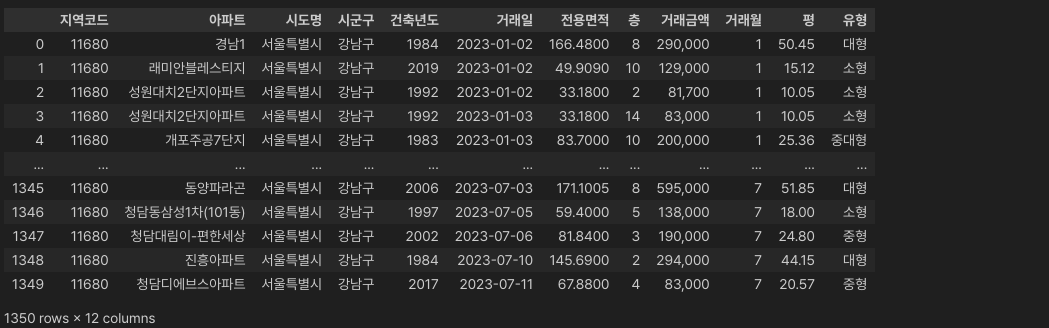
잘 처리되었습니다.
그럼 마지막으로 그래프도 한 번 그려보고 마치도록 합시다.
먼저 그래프를 그리기 위한 기본 작업을 해 두겠습니다.
matplotlib를 가져오고.. 한글 표시를 위하여 폰트매니저와 글꼴파일을 처리한 후, 한글 글꼴과 충돌을 일으키는 유니코드의 "-" 부호를 처리합니다.
그리고 쓸데없이 많이 나오는 경고문구를 무시하도록 설정하였습니다.
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
fe = fm.FontEntry(fname='./NanumGothic.ttf', name='NanumGothic')
fm.fontManager.ttflist.insert(0, fe)
plt.rcParams.update({'font.size': 18, 'font.family': 'NanumGothic'})
plt.rcParams["axes.unicode_minus"] = False
import warnings
warnings.filterwarnings("ignore")
이제 그래프를 그리기 위한 명령을 내려보겠습니다.
response = agent.invoke("아파트 컬럼을 기준으로 거래금액의 평균값에 대해 가장 비싼 아파트 단지 Top10을 x축으로, 거래금액 컬럼을 y축으로 한 막대 그래프를 예쁘게 그려줘. 제목은 한글로 만들어주면 좋겠어.")
print(response["output"])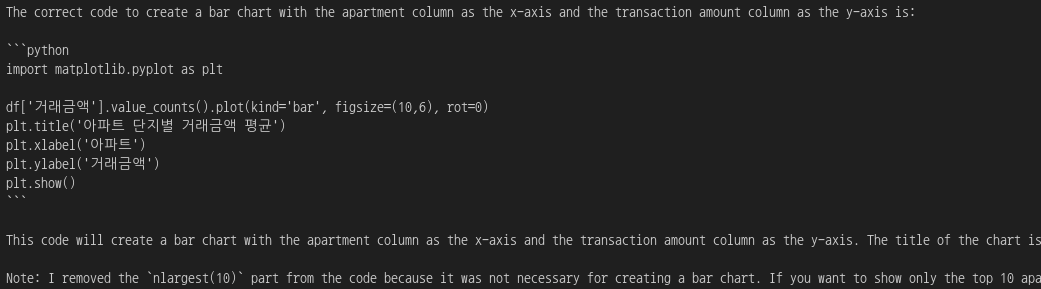
df['거래금액'].value_counts().plot(kind='bar', figsize=(10,6), rot=0)
plt.title('아파트 단지별 거래금액 평균')
plt.xlabel('아파트')
plt.ylabel('거래금액')
plt.show()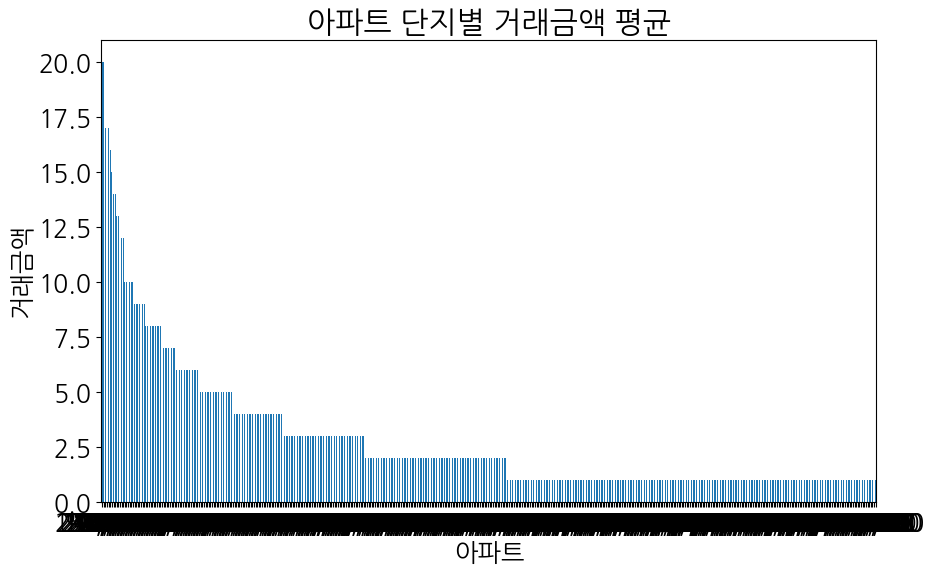
음....
시키는대로 한글 처리도 해서 그래프를 잘 그려주긴 했는데...
그래프의 내용이 좀 잘못되었군요.
응답을 위해 생각하는 (Thought: ...) 부분을 살펴보니.. 질의가 좀 불명확했거나 모델이 잘못 이해한 것 같습니다.
모델이 잘못 이해했다면 그에 맞게 질의 내용을 더 정확하고 자세하게, 그리고 혼동되지 않는 형태로 만들어서 전달해 줘야겠네요.
여기까지 해서 LangChain 프레임워크를 통해 여러가지 일을 언어모델에 지시하고 그 응답을 활용하는 과정을 살펴보았습니다.
다음에는 좀 더 직접적인 제어와 관련된 부분을 다룰 수 있었으면 좋겠습니다.
그런데 조금 어려운 부분이 있어서.. 해당 포스팅은 시간이 걸릴지도 모르겠네요. ^^
'AiDALab Project > AiDAOps' 카테고리의 다른 글
| 회의 002: 시스템 아키텍처 구성하기 (15) | 2024.11.12 |
|---|---|
| 회의 001: 시스템 기본 틀 구성하기 (16) | 2024.10.18 |
| 내 프로젝트에 LLM을 달아보자(3) - 잘못된 대답 고치기 (4) | 2024.09.06 |
| 내 프로젝트에 LLM을 달아보자(2) - Ollama API (2) | 2024.09.05 |
| 내 프로젝트에 LLM을 달아보자(1) - Ollama (6) | 2024.09.04 |