
최근 LLM(Large Language Model, 대형언어모델)에 대한 많은 관심 속에서 더욱 가볍게 학습시키고 사용할 수 있는 sLLM(smaller Large Language Model, 경량화 대형언어모델)이 주목을 받고 있죠.
얼마 전까지는 더욱 많은 파라미터를 사용하는.. 경쟁사보다 더욱 큰 모델을 개발하여 발표하는 것이 중심이었다면 최근에는 더욱 작은 모델로 더 좋은 성능을 내는 기술을 중심으로 하고 있다고 보입니다.
특히 2024년 CES와 함께 온디바이스에서의 AI와 같은 저성능의 단말기기에서 AI, 특히 LLM과 같은 기능을 지원하고자 하는 흐름이 퍼지기 시작하면서 이런 추세는 더욱 강해지고 있는 것 같습니다.
그래서 이번에는 이러한 LLM 모델들을 학습하기 위한 시스템 사양은 어떻게 되는지 질문해 보았습니다.

좀 간단하게 질문을 해 보았더니 대답 역시 명확하게 해 주지는 않네요.
이번에는 GPT4를 기준으로 하여 조금 더 상세하게 질문을 해 보았습니다.

GPT4를 기준으로 하니 위와 같은 사양을 보여줍니다.
위와 같은 간단한 목록 외에도 네트워크나 기타 사양들, 소모되는 전력량 등 더욱 많은 사양이 요구되겠지만 일단은 이런 수준으로 살펴보고 비교를 해 보겠습니다.
그럼 왠만한 기업의 자금력과 인력으로는 시도조차 하기 어려운 GPT4가 아니라 더욱 작은 모델을 기준으로 살펴보도록 하겠습니다.
최근에 발표된 sLLM 중에서 뛰어난 성능을 보이고 있는 Mistral 7B를 기준으로 살펴볼까요?
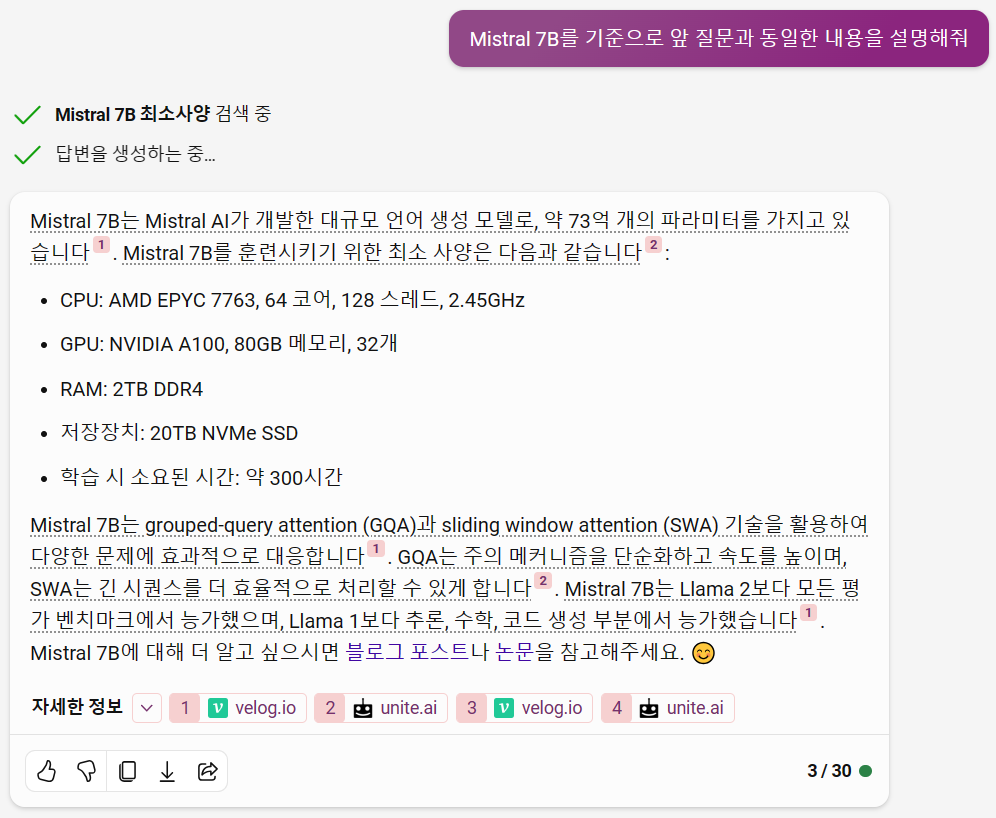
OpenAI의 GPT4에 사용된 사양보다는 조금 더 저렴한 AMD CPU를 사용하고 있습니다.
그러나 코어의 수와 스레드의 수를 보면 오히려 더 늘어난 것이 아닌가.. 생각이 듭니다.
Intel Xeon Platinum 8380M과 AMD EPYC 7793의 성능을 비교해 봐야 더 정확하겠지만 거기까지는 필요없을 것 같네요.
비용에 가장 큰 영향을 미치는 NVIDIA GPU는 둘 다 동일한 A100 80GB 메모리 타입을 사용하고 있군요.
GPU의 수는 32개로 GPT4가 사용한 40개보다 줄었습니다.
비용이 조금 떨어지긴 하겠군요.
메모리는 GPT4의 1.5TB보다 더 많은 2TB를 사용하고 있습니다.
저장장치 역시 2배나 많이 사용하고 있으며 학습 소요시간은 조금 줄었네요.
Mistral 7B의 경우는 GPT4보다 상당히 작아진 모델인데 요구되는 컴퓨터의 사양은 크게 차이가 나지 않아 보입니다.
여전히 일반적인 기업이나 개인이 접근하기는 어려워 보입니다.
그럼 이번에는 바로 며칠 전(2024년 1월 19일, 현지시간)에 발표된 따끈따끈한 sLLM 모델을 살펴보도록 하겠습니다.
그림을 그려주는 AI 모델로 유명한 Stable Diffusion WebUI를 개발한 Stability AI사에서 새로운 sLLM로 개발한 Stable LM 2 시리즈의 첫 번째 언어 모델인 Stable LM 2 1.6B 모델을 발표했습니다.
Stable LM 2 1.6B 모델은 16억 개 매개변수를 가진 기본 모델에 인스트럭션 튜닝(특정의 지시에 근거해 튜닝한)을 적용한 버전입니다.
Mistral 7B보다 훨씬 적은 1.6B의 매개변수를 가지고 있으니 더욱 소규모의 시스템에서도 학습이 가능할 것 같네요.
그럼 Stable LM 2 1.6B를 기준으로 살펴보겠습니다.

위와 같은 사양을 가진 것으로 설명하고 있습니다.
CPU는 GPT4와 동일한 사양, 동일한 수준을 유지하고 있습니다.
GPU는 GPT4와 동일한 모델을 사용하고 있지만 16개를 사용하고 있으니 GPT4의 40%에 불과한 규모를 가지고 있네요.
사용된 RAM도 GPT4의 1.5TB보다 적은 1TB를 사용하고 있습니다.
저장장치의 용량도 절반에 그치네요.
전반적으로 GPT4에서 사용한 것과 동일한 모듈로 구성했지만 그 규모가 줄어든 것을 볼 수 있습니다.
마지막으로 학습 소요 시간도 GPT4의 355시간에 비해 약 56%에 해당하는 200시간 정도를 사용한 것을 확인할 수 있었습니다.
확실히 규모는 많이 줄어들었네요.
그럼 여기에 사용된 비용은 얼마나 될까요?
이게 가장 중요해 보입니다.
전체적인 비용을 살펴보는 것은 어려우니까 간단하게 GPU 모듈이 얼마를 요구하는지만 살펴보고 전체적으로 감을 잡는 것이 좋겠습니다.
그래서 위의 시스템들이 사용한 GPU 모듈의 가격을 물어보았습니다.
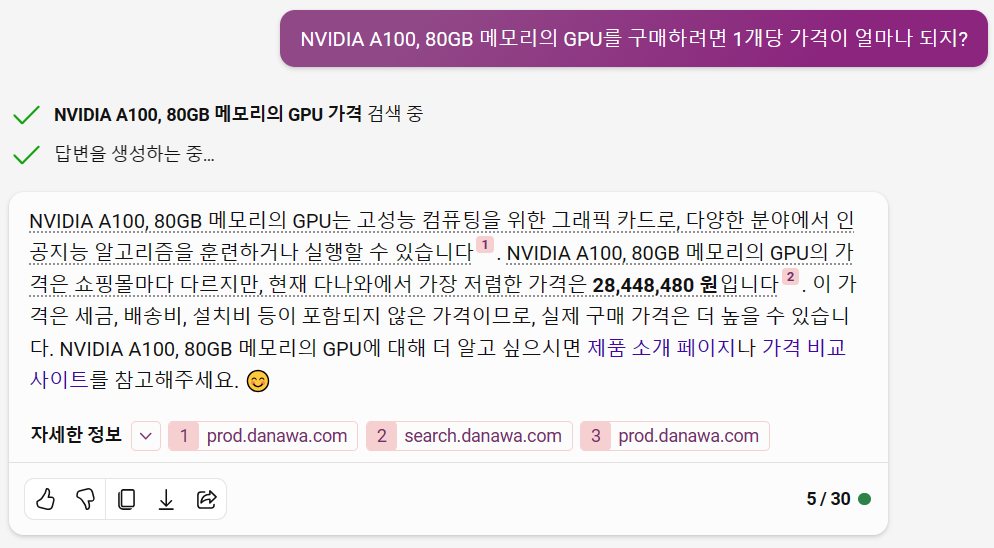
NVIDIA A100 80GB의 GPU 모듈 하나의 가격이 약 3천만원이 되네요.
Stable LM 2 1.6B에 사용된 16개를 계산하면 약 4억8천만원~5억원 정도가 요구되고 있습니다.
기업의 규모라고 하면 중소기업들에게는 조금 부담이 되긴 하겠지만 불가능한 정도까지는 아니겠네요.
개인이라고 한다면.... 재벌이나 준재벌이 아니라면 사실상 불가능해 보입니다. ㅠㅠ
그런데 가끔 개인이 sLLM을 개발하여 "Open Ko-LLM 리더보드" 등에 오르는 경우는 어떻게 하는 것일까요?
사실 이 경우는 앞에서 살펴본 내용과는 조금 다르게 생각을 해야 합니다.
지금까지 살펴본 시스템의 사양은 해당 LLM 또는 sLLM 모델을 처음부터 구축, 학습을 진행한 경우라고 본다면, 최근에 리더보드 등에서 볼수 있는 모델들은 LLAMA2와 같은 모델이 학습한 결과물을 기반으로 추가학습을 진행하거나 내용을 조정하거나.. 기타 여러 작업을 거쳐서 만든 경우가 많습니다.
그래서 앞에서 본 어마어마한 사양의 시스템까지는 필요없는 경우가 많습니다.
그리고 찾아보면 의외로 무료, 또는 저렴한 가격으로 GPU를 제공하는 서비스들이 많이 있습니다.
이런 서비스를 활용해서 최소한의 비용으로 진행하고 있다고 보는 것이 좋습니다.
물론 직접 많은 투자를 해서 프로젝트를 수행하는 일부 기업이나 기관도 많이 있겠지만 개인의 입장에서는 최대한 지원받을 수 있는 방법을 찾는 것이 좋겠죠.
지금까지 만약 우리가 sLLM / LLM을 개발, 학습(훈련)시킨다면 어떤 사양의 시스템을 고려해봐야 할까.. 라는 주제로 한 번 조사를 해 보았습니다.
'AiDALab Project > AiDAOps' 카테고리의 다른 글
| Tensorflow를 위한 GPU 설정 포기! 그냥 PyTorch로 가야겠다. (0) | 2024.06.09 |
|---|---|
| AiDAOps개발 시 적용할 DB관련 조사 (3) | 2024.01.26 |
| 작업 계획을 위한 관련 정보의 사전조사를 LLM으로 하면 편하겠다 (2) | 2024.01.24 |
| DevOps와 MLOps (2) | 2023.12.10 |
| AI 모델 경량화 (6) | 2023.05.16 |