
(이 글은 이번에 병행 운영하던 2개의 블로그를 통합하면서 기존 블로그의 내용을 일부 수정하여 옮겨온 글입니다.)
일반적으로 주식투자 관련 데이터를 사용하려면 각 증권사 계좌를 만들고 해당 증권사에서 제공하는 API를 사용하여 데이터 수집을 진행합니다.
그러나 그것때문에 일부러 증권계좌를 만드는게 좀 꺼려지는 경우도 많을것입니다.
그런 경우에는 네이버 또는 다음과 같은 포탈서비스에서 제공하는 금융, 증권서비스를 이용하는 것도 좋습니다.
그러나 포탈서비스 업체에서는 증권사에서 제공하는 API와 같은 특화된 서비스를 제공하지는 않습니다.
그렇다면 우리가 생각해 볼 수 있는 것은 웹 스크레이핑과같은 기술이 되겠군요.
이번 글에서는 파이썬을 이용하여 웹 스크레이핑 기술을 활용한 주가 데이터 받아오기를 해 보겠습니다.
일반적으로 어떻게 값들을 읽어오는지 살펴보기 위해서 Victorr 님의 블로그에서 "파이썬으로 네이버 금융에서 주가 데이터 받기" (http://blog.naver.com/PostView.nhn?blogId=zakk81&logNo=221110640599) 포스트를 참고하였습니다.
소스코드는 그대로 사용하지 않고 약간씩 수정해서 사용하고 있습니다.
구현 방식에 대하여 조금 더 익숙해지면 그 때는 직접 다 구현해 볼 예정입니다.
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
%matplotlib inline
corp_code = '206650'
for page in range(1, 21):
url_tmp = 'http://finance.naver.com/item/sise_day.nhn?code=%s&page=%s'
url = url_tmp % (corp_code, page)
html = requests.get(url).text
html = html.replace('\n', '')
html = html.replace('\t', '')
html = html.replace(',', '')
html = html.replace('.', '-')
soup = BeautifulSoup(html, 'lxml')
span_data = soup.find_all('span')
td_data = soup.find_all('td')
tr_data = soup.find_all('tr')
th_data = soup.find_all('th')
if page == 1:
columns_list = []
for i in range(len(th_data)):
i_text = th_data[i].text
columns_list.append(i_text)
stock_price_all_array = np.array([columns_list])
rest_page = 0
stock_price_list = []
for i in range(1, len(span_data)):
a = span_data[i].text
stock_price_list.append(a)
if page > 1 and stock_price_list[0] == stock_price_all_array[-10, 0]:
rest_page = (21 - page) * 10
stock_price_array = np.zeros((rest_page, 7))
stock_price_all_array = np,append(stock_price_all_array, stock_price_array, axis=0)
break
if i % 7 == 0:
stock_price_array = np.array([stock_price_list])
stock_price_all_array = np.append(stock_price_all_array, stock_price_array, axis=0)
stock_price_list = []
if rest_page:
break
elif len(span_data) < 70:
rest_row = int((70-len(span_data)) / 7 + 1)
stock_price_array = np.zeros((rest_row, 7))
stock_price_all_array = np.append(stock_price_all_array, stock_price_array, axis=0)
rest_page = (21 - page - 1) * 10
stock_price_array = np.zeros((rest_page, 7))
stock_price_all_array = np.append(stock_price_all_array, stock_price_array, axis=0)
break
stock_price_all_array = np.delete(stock_price_all_array, 0, 0)
stock_price_all_df = DataFrame(stock_price_all_array, columns=columns_list).set_index('날짜')
print(stock_price_all_df)
위의 코드대로 수행해보면 '날짜', '시가', '종가', '고가', '저가', '전일비', '거래량'으로 이루어진 데이터를 얻을 수 있습니다.(코드가 몇 줄 다른 것은 그래프를 그리기 위함입니다.)
아무래도 그래프가 보기 쉬우니 그래프를 그려보도록 하죠.
그래프를 그리려고 하면 DataFrame에서 숫자로 된 데이터가 없다는 오류가 발생하는데 네이버 금융 포탈 서비스에서 HTML 형태의 결과를 받아와서 일부 파싱하여 DataFrame으로 만들었기 때문에 각 항목들이 공백문자를 포함하고 있어서 숫자로 인식하지 않는 것입니다.
파싱할 때 공백을 제거해 주거나 기타 방법을 적용하면 문제 없는데 저는 그냥 간단하게 CSV 파일로 저장하고 다시 읽어 들이는 무식한 방법을 사용하였습니다.
stock_price_all_df.to_csv('./data.csv')
stock_df = pd.read_csv('./data.csv')
# print(stock_df)
plt.figure(figsize=(15, 6))
plt.plot(stock_df['종가'])
plt.plot(stock_df['시가'])
plt.show()
plt.figure(figsize=(15, 6))
plt.plot(stock_df['고가'])
plt.plot(stock_df['저가'])
plt.show()
plt.figure(figsize=(15, 6))
plt.plot(stock_df['거래량'])
plt.show()
위의 코드처럼 작성하여 실행해 보면 아래와 같은 그래프를 볼 수 있습니다.
전체 데이터는 180일 간의 데이터입니다.
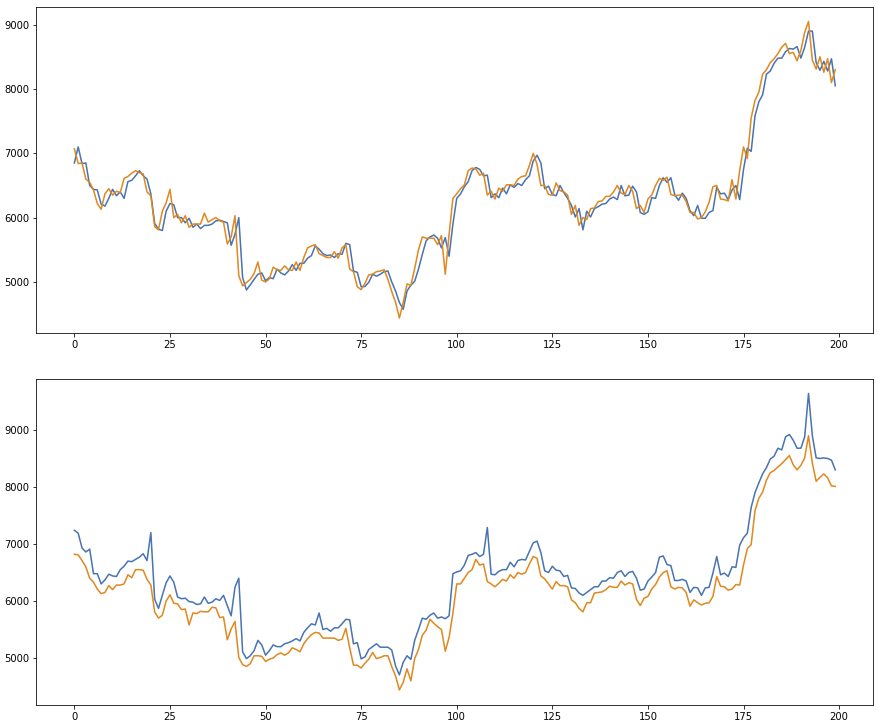

가장 위의 그래프는 시가와 종가를 보여주고 두 번째 그래프는 저가와 고가를 보여줍니다.
두 번째 그래프의 저가, 고가 데이터로 해당 주가가 거래되는 범위를 확인할 수 있는데, 이러한 범위를 이용하여 밴드를 계산하면 향후 주가 거래 범위 및 변동 추세를 예측할 때 활용할 수 있습니다.
마지막 그래프는 6개월 간의 거래량을 보여주는데 보자마자 알 수 있듯이 3번의 거래량 급증이 확인되죠.
거래량의 급증은 대량 매수 및 매도가 일어난 시점이며 해당 시점에서의 주가를 확인해 보면 어떤 상황이었는지 알 수 있습니다.
기본적인 데이터는 위와 같은 방법으로 확보, 가공할 수 있고 점차 데이터의 양과 종류를 늘리고 분석기법을 하나씩 적용해 가면서 시스템을 구현해 나갈 것입니다.
그리고 기업 분석을 위한 재무제표 및 기타 정보들도 어떻게 통합하고 분석할 것인지 방향을 잡아 나갈 계획입니다.
'AiDALab Project > AiDA Stocks' 카테고리의 다른 글
| 네이버에서 모든 종목의 재무제표를 받아서 비교하기 (8) | 2019.11.29 |
|---|---|
| 네이버에서 현금흐름표 데이터 받아오기 (0) | 2019.11.29 |
| 네이버에서 재무제표 데이터 받아오기 (4) | 2019.11.29 |
| 주가지수 종목에 대한 투자 실험 진행 중 (0) | 2019.11.29 |
| 주식 투자를 할 때 종목 선택의 어려움에 대하여 (0) | 2019.11.29 |