
(이 글은 이번에 병행 운영하던 2개의 블로그를 통합하면서 기존 블로그의 내용을 일부 수정하여 옮겨온 글입니다.)
기업의 상태를 분석하기 위해서 가장 중요하면서 또한 기본이 되는 데이터가 바로 재무제표입니다.
재무제표를 분석하기 위하여 일단 그 데이터를 받아와야 하는데 주가데이터와 마찬가지로 네이버 금융 서비스에서 데이터를 받아오도록 합시다.
소스코드는 아래의 두 포스트를 참고 및 비교하였습니다.
1. '나는 새롭다' 님의 블로그의 '[Python 재무제표 크롤링 #7] NAVER 금융에서 재무제표 데이터, 파이썬 데이터 프레임으로 추출하기' (https://engkimbs.tistory.com/625)
2. '데이터 큐레이터'님의 블로그의 '[파이썬 업무 자동화] 상장사 재무제표 수집(pandas)' (https://pydata.tistory.com/19)
이번에 테스트 하는 재무제표의 대상은 삼성전자(005930)입니다.
코드 1. (from 네이버 금융, '나는 새롭다' 님의 블로그)
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
url_tmpl = 'https://finance.naver.com/item/main.nhn?code=%s'
url = url_tmpl % ('005930')
item_info = requests.get(url).text
soup = BeautifulSoup(item_info, 'html.parser')
finance_info = soup.select('div.section.cop_analysis div.sub_section')[0]
th_data = [item.get_text().strip() for item in finance_info.select('thead th')]
annual_date = th_data[3:7]
quarter_date = th_data[7:13]
finance_index = [item.get_text().strip() for item in finance_info.select('th.h_th2')][3:]
finance_data = [item.get_text().strip() for item in finance_info.select('td')]
finance_data = np.array(finance_data)
finance_data.resize(len(finance_index), 10)
finance_date = annual_date + quarter_date
finance = pd.DataFrame(data=finance_data[0:,0:], index=finance_index, columns=finance_date)
코드 2. (from KINLINE (Nice평가정보 에서 운영하는 서비스), '데이터 큐레이터'님의 블로그)
import pandas as pd
url_tmpl = 'http://media.kisline.com/highlight/mainHighlight.nice?nav=1&paper_stock=%s'
url = url_tmpl % ('005930')
tables = pd.read_html(url)
df = tables[4]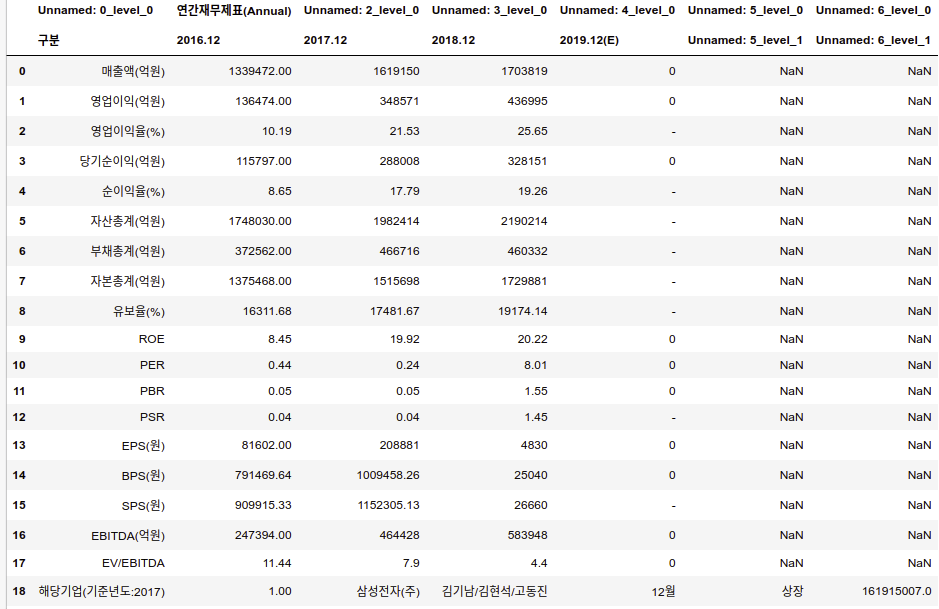
코드 2가 훨씬 간단하군요.
코드 2에 데이터 소스 경로를 네이버 금융으로 바꾸고 다시 확인해 보았습니다.
코드 3. (from 네이버 금융, 코드2 기반)
import pandas as pd
url_tmpl = 'https://finance.naver.com/item/main.nhn?code=%s'
url = url_tmpl % ('005930')
tables = pd.read_html(url, encoding='euc-kr')
df = tables[3]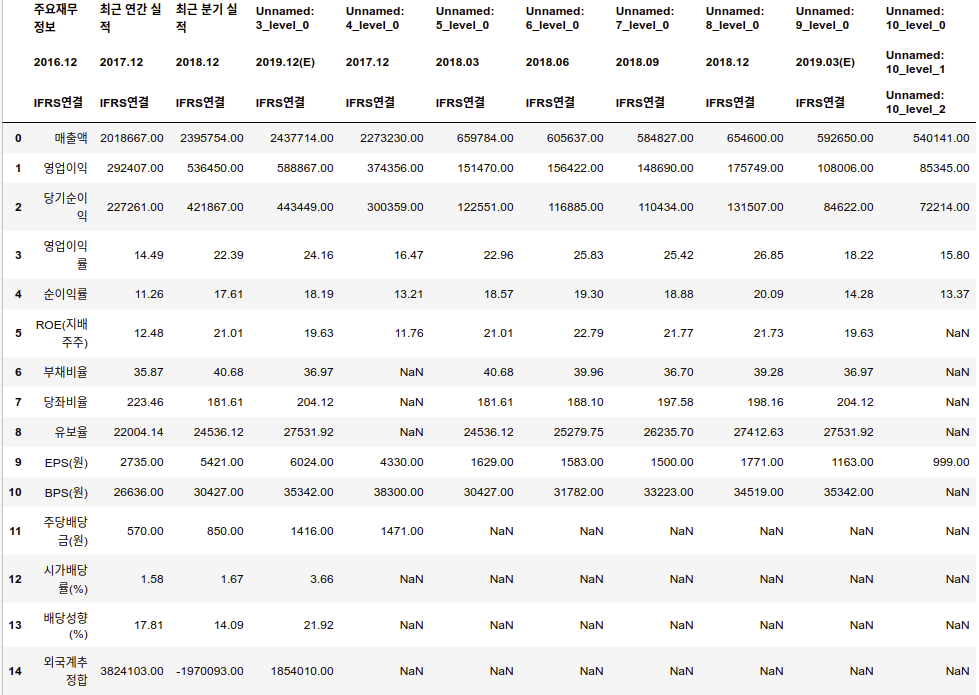
경로를 변경해도 잘 동작합니다.
단, 코드 1에서는 requests 모듈의 get(url)을 이용하여 데이터를 받아 왔고 아무런 문제 없이 확인이 가능하지만 코드 3에서는 한글이 깨지는 현상이 발생합니다.
코드 2의 KISLINE은 문자셋의 인코딩을 'UTF-8' 을 사용하고 있지만 네이버 금융의 경우는 'EUC-KR' 을 사용하고 있기 때문에 일어나는 문제입니다.
코드 2와 코드 3에서는 Pandas의 read_html()을 사용하므로 네이버 금융에서 데이터를 받아 올 때는 pd.read_html(url, encoding='euc-kr') 와 같이 인코딩을 지정해 주어야 합니다.
또 한 가지, 코드 2에서 받은 KISLINE의 테이블 데이터에서는 다섯 번째 배열, 즉 tables[4]에 재무제표의 데이터가 들어있지만 코드 3에서 받은 네이버 금융의 테이블 데이터에서는 네 번째 배열, 즉 tables[3]에 재무제표의 데이터가 들어있습니다.
이 두 가지만 확인한다면 코드 3과 같이 짧은 코드로 재무제표 데이터를 받아오는 것이 가능하네요.
그런데..........
같은 기업(삼성전자), 같은 기간의 재무제표를 받아왔는데... 어째서 네이버 금융과 KISLINE의 데이터가 다른지??
- 2017년 매출액: 네이버 금융 -> 2,018,667 KISLINE -> 1,339,472
- 2018년 매출액: 네이버 금융 -> 2,395,754 KISLINE -> 1,619,150
KISLINE은 유료서비스던데... 그래서 비 회원에게는 샘플데이터를 보내주는걸까요?? 잘 모르겠네요...
'AiDALab Project > AiDA Stocks' 카테고리의 다른 글
| 네이버에서 모든 종목의 재무제표를 받아서 비교하기 (8) | 2019.11.29 |
|---|---|
| 네이버에서 현금흐름표 데이터 받아오기 (0) | 2019.11.29 |
| 네이버에서 주가 데이터 받아오기 (1) | 2019.11.29 |
| 주가지수 종목에 대한 투자 실험 진행 중 (0) | 2019.11.29 |
| 주식 투자를 할 때 종목 선택의 어려움에 대하여 (0) | 2019.11.29 |