

현재 개발되고 사용되는 대형언어모델(LLM)의 기반은 트랜스포머(Transformer)아키텍처입니다.
LLM이 점점 커지고 고도화되면서 트랜스포머 아키텍처의 기반이 되는 어텐션 모델의 한계에 대한 논의도 계속되고 있죠.
그래서 어텐션 기반의 트랜스포머 아키텍처를 개선하거나 대체하겠다는 연구, 개발도 지속되고 있습니다.
미국의 AI 스타트업 매니페스트 AI는 4일(현지시간) ‘브럼비(Brumby)’ 모델을 온라인 아카이브를 통해 소개하였고, 해당 모델에서는 트랜스포머 아키텍처에서 어텐션 레이어를 완전히 제거하고 자사가 개발한 파워 리텐션(Power Retention) 아키텍처를 적용하여 트랜스포머 아키텍처의 문제를 해결, 개선했다고 주장하고 있으며, 트랜스포머 아키텍처를 대체할 것이라고 밝혔습니다.
https://www.aitimes.com/news/articleView.html?idxno=203746
‘어텐션’ 없는 새로운 AI 아키텍처 '파워 리텐션' 등장 - AI타임스
대형언어모델(LLM)의 기반이 되는 '트랜스포머(Transformer)'를 대체하는 새로운 아키텍처가 또 등장했다. 미국 인공지능(AI) 스타트업 매니페스트 AI
www.aitimes.com
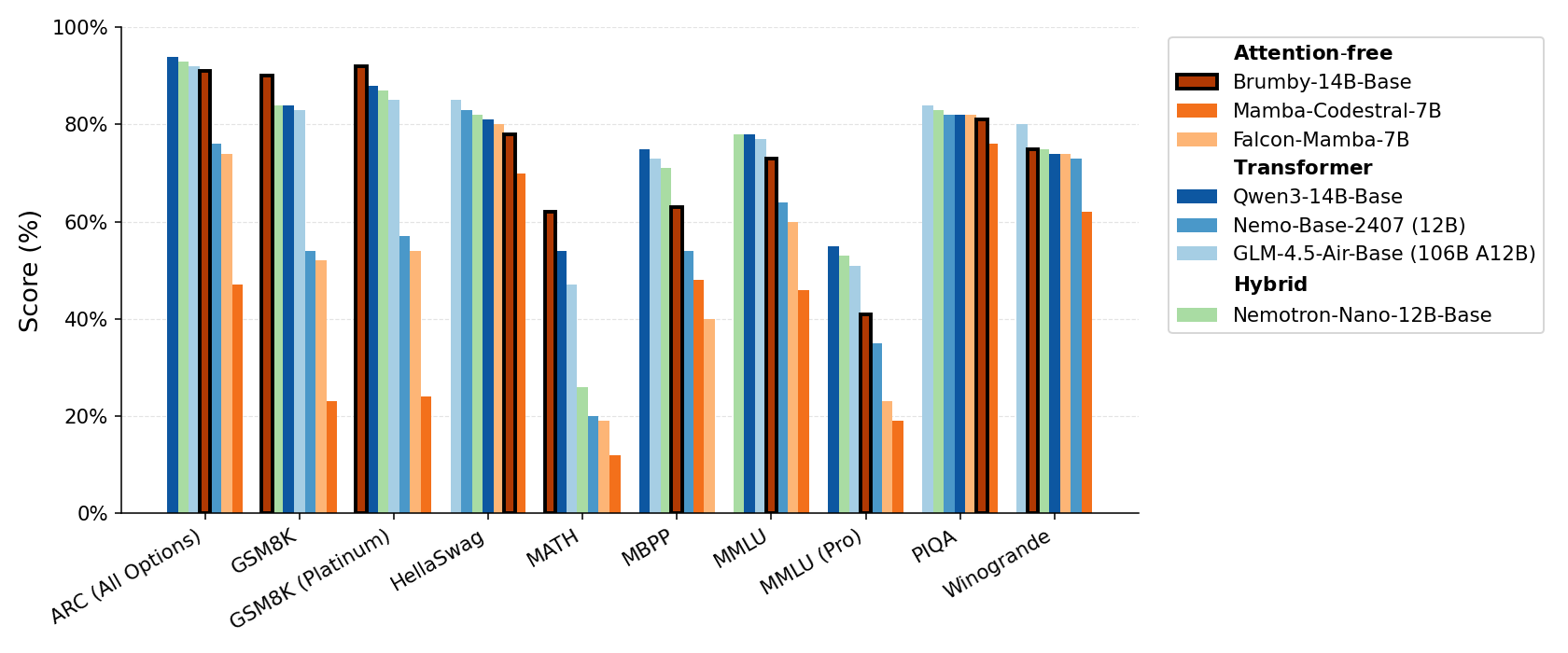
매니페스트 AI의 주장대로라면 LLM 기술은 한 단계 더 성장한다고 볼 수 있겠죠.
그런데 과연 트랜스포머 아키텍처의 대체 기술이라고 할 수 있을지 아직 의문이 남습니다.
가장 큰 의문점은 바로 RNN(Recurrent Neural Network, 순환신경망) 기반의 모델을 적용했다는 것이고, 두 번째 의문점은 전이학습을 이용한다는 점입니다.
먼저 첫 번째 의문점에 대하여 생각해 보면...
트랜스포머 아키텍처의 기반이 되는 어텐션 모델은 원래 RNN이 가지는 장기의존성 문제를 해결하기 위해서 개발된 모델입니다.
전통적인 RNN은 기울기 소실(Vanishing Gradient)이나 폭주(Exploding Gradient) 문제로 인해 장기 의존성 학습이 어려웠고, 이를 해결하기 위하여 중요한 부분에 집중하는 어텐션 기법을 적용하게 된 것이죠.
그런데 다시 어텐션 모델을 제거하고 RNN 방식으로 돌아간다..라는 것이 사실 납득하기가 조금 어렵습니다.
물론 전통적인 방식의 RNN 모델을 그대로 사용하는 것은 아니고 "지속적인 업데이트"라는 새로운 방식을 적용했다고 하는데.. 그렇게 쉽게 해결이 될까.. 의문이 생깁니다.
RNN 모델은 모델을 구성하는 공식 자체가 가지고 있는 문제때문에 기울기 소실, 폭주 등의 문제가 발생하는 것이라서 LSTM(Long Short-Term Memory)과 같은 일부 요소를 완전히 제거하고 변형한 후속 모델들이 줄줄이 나왔던 것이니까요.
RNN 기반이라고 했으니 LSTM과 같이 근본적인 문제를 해결한 RNN 계열의 모델 방식을 적용했다.. 라고 할 수도 있긴 합니다.
만약 매니페스트 AI의 주장이 사실이라면, 파워 리텐션은 다음과 같은 이점을 가질 수 있겠죠.
- 효율적인 연산: 어텐션 메커니즘 제거로 인한 연산 비용 감소
- 긴 시퀀스 처리: 전통적인 RNN과 다른 방식의 "지속적인 업데이트"를 통해 장기 의존성을 해결하여 더 긴 문맥을 효과적으로 처리
- 유연한 컨텍스트: 고정된 컨텍스트 윈도우가 아닌, 지속적으로 정보를 갱신하는 방식으로 훨씬 유연하게 컨텍스트를 다룰 수 있음
그러나 아직 그 과정이 명확하지 않고, 추가적인 검증이 필요해 보입니다.
두 번째 의문점을 생각해 봅시다.
메니페스트 AI가 허깅페이스에 공개한 내용을 보면 자신들의 모델은 트랜스포머 아키텍처에서 학습된 가중치를 재활용한다고 밝히고 있습니다.
https://huggingface.co/manifestai/Brumby-14B-Base
manifestai/Brumby-14B-Base · Hugging Face
Brumby-14b-base Model Developer: Manifest AI Number of Parameters: 14B Release Page: https://manifestai.com/articles/release-brumby-14b/ Model Overview Brumby-14b-base is a completely attention-free LLM whose performance is competitive with state-of-the-ar
huggingface.co
파워 리텐션 모델이 "재훈련(retraining)"이라는 방식을 통해 사전 학습된 트랜스포머의 가중치를 활용한다는 점을 고려할 때, 이를 트랜스포머 아키텍처의 완전한 대체라고 보기는 어렵지 않나.. 라는 것입니다.
물론 전이학습이라는 방법은 제대로 인정받는 모델 학습 방법인 것은 맞습니다.
그런데 이 경우.. 트랜스포머 아키텍처를 대체했다.. 라고 할 수 있을까요?
학습은 트랜스포머 아키텍처로 수행하고, 그 결과 가중치에 대한 활용만 파워 리텐션 모델이 담당하는 것으로 볼 수 있지 않을까요?
완전히 트랜스포머 아키텍처를 대체한다면 학습, 정보 통합 과정도 파워 리텐션 모델이 담당해야 할 것으로 생각됩니다.
그러나 사전 학습된 트랜스포머의 가중치를 "재훈련"하여 사용한다는 것은, 모델이 학습하는 초기 지식의 원천이 결국 트랜스포머 아키텍처에 의해 형성된 것임을 의미합니다.
이는 파워 리텐션이 독립적으로 대규모 데이터를 학습하여 새로운 지식 표현 방식을 생성한 것이 아니라, 트랜스포머가 축적한 지식을 효율적으로 전이 받아 활용하는 단계에 있다고 해석할 수도 있는 문제입니다.
현재로서는 파워 리텐션이 트랜스포머 아키텍처의 학습된 지식을 활용하는 후속 모델 또는 변형 아키텍처라고 보는 것이 더 적절해 보이며, 이는 완전히 새로운 아키텍처가 독자적인 지식을 쌓아 트랜스포머를 능가하는 '대체'와는 차이가 있다고 생각됩니다.
만약 파워 리텐션이 트랜스포머 가중치 없이 제로에서부터 대규모 데이터로 사전 학습하여 트랜스포머와 동등하거나 더 나은 성능을 보여줄 수 있다면, 그때는 명실상부한 '대체 아키텍처'라고 주장할 수 있을 것입니다.
그렇지만 이러한 접근 방식 자체가 어텐션의 고질적인 문제를 해결하여 AI 모델의 활용도를 넓히는 데 크게 기여할 잠재력이 있다는 점을 간과할 수 없는 것은 확실합니다.
문제가 있어서 대체된 지난 모델이라고 해도 개선 방법과 응용 방법의 변화를 통해 새롭게 평가받을 가능성은 있으니까요.
현재의 LLM을 뛰어넘고자 하는 다양한 모델, 아키텍처와 아이디어들이 쏟아져 나오고 있습니다.
어떤 기술이 최종적인 선택을 받게 될 지는 아직 모르지만 AI 분야에서 다양한 가능성이 등장하는 중요한 시기로 보입니다.
부디 이러한 흐름에 뒤처지지 않고 시대를 잘 따라갈 수 있었으면.. 하고 바라고 있는 요즘입니다.

'AI & IT' 카테고리의 다른 글
| CES 2026에서 보이는 피지컬 AI와 에이전틱 AI의 중요도 (0) | 2026.01.13 |
|---|---|
| 일회용 앱(Disposable Apps)...인가.. (0) | 2025.11.01 |
| LLM 다양성 높이는 ‘버벌라이즈드 샘플링’ 기법..이라고? (1) | 2025.10.21 |
| 바이브 코딩은 저물어 가는가? (0) | 2025.10.04 |
| GPT-OSS / GPT-5의 발표.. 그 밑에 깔린 OpenAI의 전략은 무엇일까? (20) | 2025.08.09 |