
얼마 전에 식빵을 굽다가 후라이팬을 태워먹은 적이 있습니다.
정확히는 후라이팬이 탄 것은 아니고 식빵이 타면서 후라이팬에 눌어붙은 것입니다만...
여러가지 방법을 시도해 봤지만 깨끗하게 지워지지 않았는데 이번에 생성형 AI들에게 흔하게 잘 알려진 생활 팁에 대한 질문을 하면 얼마나 잘 대답해 줄까? 라는 것이 궁금해 졌습니다.
그래서 GPT-3.5, GPT-4, Bing AI, Bard에게 각각 질문을 해 보았습니다
탄 냄비를 깨끗하게 씻으려면 어떻게 해야 하지?
사실 어떤 데이터로 학습이 되었는가?에 따라, 그리고 입력 프롬프트에 따라 어떤 데이터가 가장 높은 확률로 뽑혔는가?에 따라서 결정되는 것이기때문에 엄밀하게는 생성형 AI의 정확성이라고 하는것은 좀 억지스럽긴 합니다만...
어쨋든 학습된 결과도 포함해서 AI모델인 것이니까 한 번 비교해 보았습니다.
- 먼저 GPT-3.5의 경우

뭔가... 탄 냄비를 깨끗하게 씻는 방법이 아니라 일반적인 설거지 방법을 제시하고 있네요.
완전히 틀렸다고는 할 수 없고... 뭐.. 저렇게 씻을 수도 있지만 그다지 만족스럽지는 않은 대답입니다.
- GPT-4의 경우

GPT-3.5 보다는 훨씬 원하는 답에 가깝습니다.
그리고 각 방법에 대하여 보다 상세하게 대답을 하고 있습니다.
확실히 내용의 정확도나 그런 문제에서는 GPT-4가 훨씬 잘 대응하는 것 같습니다.
- Bing AI의 경우
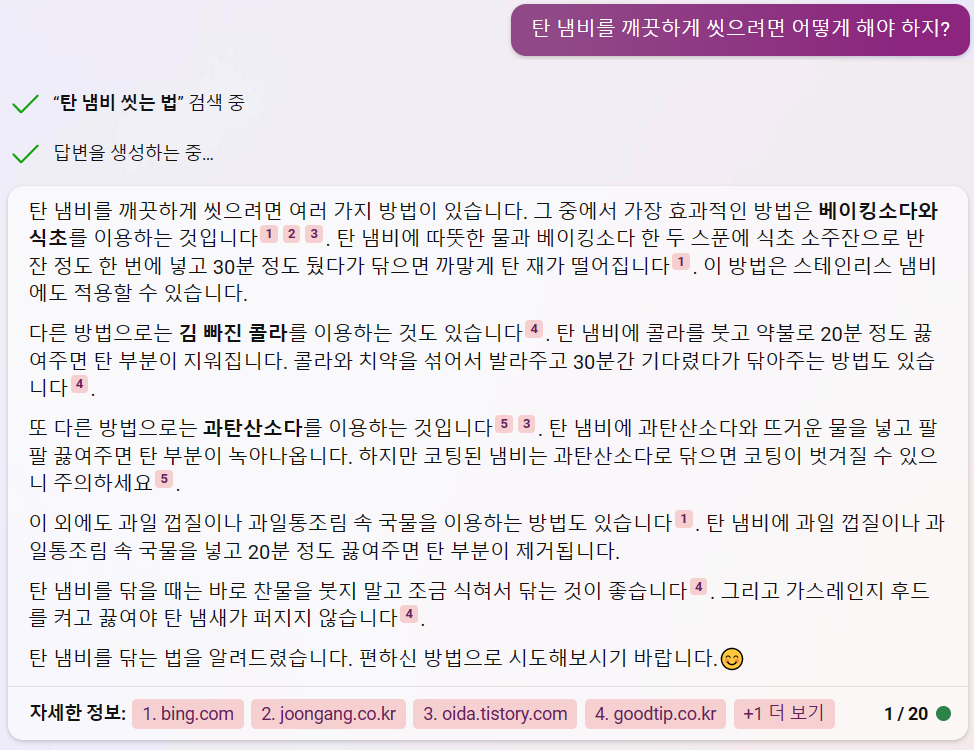
Bing AI도 원하는 결과를 잘 보여주고 있습니다.
GPT-4보다는 덜 상세하지만 GPT-4보다 더 다양한 방법을 제시하고 있다는 것이 흥미롭군요.
아무래도 실제로 웹에서 검색한 내용을 기반으로 대답을 만들고 있으니 훨씬 더 보편적인 방법들을 잘 제시하고 있습니다.
- Bard의 경우
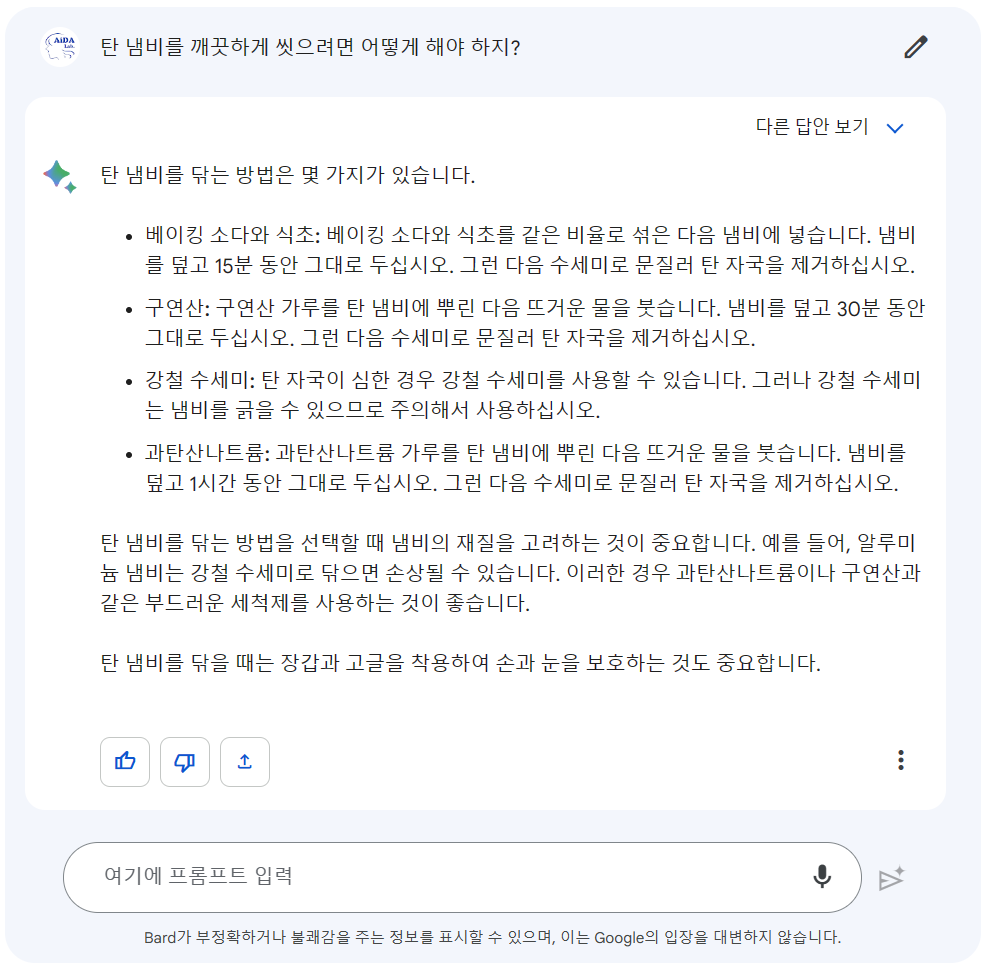
Bard의 경우도 제대로 된 대답을 내놓고 있습니다.
그러나 강철 수세미로 박박 긁으라는... 다소 과격한 내용을 포함시키고 있다는 점이 독특하네요.
이상과 같이 간단한 문제를 가지고 각 생성형 AI를 비교해 보았습니다.
GPT-3.5의 경우는 매우 거대한 데이터를 기반으로 학습이 진행되었다고 하지만...
사실이 아닌 것을 사실처럼 말하는 할루시네이션 현상이 GPT-3.5에서 특히 많이 일어난다고 알려진 것처럼..
뭔가 조금 어긋난 결과가 생성되는 경향이 좀 더 강해보입니다.
GPT-4, Bing AI, Bard의 경우는 대체로 원하는 결과를 잘 도출하는 모습을 보여주고 있네요.
GPT-4는 좀 더 상세하게, 세세한 대답을 만들어 내고 있고, Bing AI와 Bard는 보편적인 내용을 중심으로 좀 더 폭젋은 시각으로 대답을 만들어 내고 있는 것으로 보입니다.
앞에서 언급한 것처럼 학습된 데이터와 입력 프롬프트, 그리고 학습 시에 어떤 가중치 맵을 만들어 냈는가에 따라서 그 결과가 달라지고, 또 위의 내용은 극히 일부의 예시에 지나지 않기 때문에...
이 번에 비교한 단순한 내용으로 생성형 AI들을 평가하거나 그 특징을 일반화하는 것은 문제가 있다고 보입니다.
그러나 각 생성형 AI들이 왠지 모를 제 나름대로의 특징이 있다고 생각해보면 좀 더 재미있게 접근할 수 있지 않을까.. 싶습니다.
'AI 기반 이론' 카테고리의 다른 글
| 어제는 주식 종목 추천은 안한다더니 오늘은 말을 바꾸는 안드로이드 Bing AI 앱 (0) | 2023.05.22 |
|---|---|
| 구글의 Bard가 Bing AI보다 구글 기술을 모른다?? (2) | 2023.05.21 |
| Bing AI와 Bard가 추천하는 RTX모델은? (4) | 2023.05.19 |
| ChatGPT 유료 신청 (0) | 2023.05.16 |
| Bard 시범 서비스를 사용해 보았다 (0) | 2023.04.19 |