
이번 글에서는 CNN 모델 구현코드의 기본 형태를 알아보겠습니다.
사실 CNN 모델의 구현도 DNN 모델, 그러니까 기본 딥러닝 모델의 구현과 다르지 않습니다.
Keras에서 제공하는 레이어들을 원하는 순서로 배치하기만 하면 됩니다.
이번에는 x의 2차방정식이 아닌.. 딥러닝을 처음 접할때 겪게 되는 대표적인 예제인 MNIST와 아이리스(창포꽃) 분류 예제 중에서 아이리스의 분류를 훈련데이터로 사용해 보겠습니다.
아이리스 분류 예제는 워낙 유명해서 여러 라이브러리에서 그 데이터를 이미 포함시켜놓고 있습니다.
여기에서는 사이킷런(scikit-learn) 라이브러리를 사용하도록 하겠습니다.
그럼 먼저 전체 코드를 살펴봅시다.
import numpy as np
from tensorflow import keras
from tensorflow.keras.layers import Dense, Conv1D, Flatten
from sklearn.datasets import load_iris
iris = load_iris()
x = iris['data']
y = iris['target']
train_x, test_x = x[:120], x[120:]
train_y, test_y = y[:120], y[120:]
train_x = np.reshape(train_x, (120, 4, 1))
test_x = np.reshape(test_x, (30, 4, 1))
model = keras.Sequential()
model.add(Conv1D(4, 3, activation='relu', input_shape=(4,1)))
model.add(Flatten())
model.add(Dense(10, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(3, activation="softmax"))
model.compile(optimizer="SGD", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
model.summary()
model.fit(train_x, train_y, epochs=1000, verbose=0, batch_size=20)
loss, acc = model.evaluate(test_x, test_y)
result = model.predict(test_x)
print(result)
print(np.argmax(result, axis=1))필요한 라이브러리를 import하는 부분은 이제 잘 아실테니 넘어가도록 하죠.
iris = load_iris()
x = iris['data']
y = iris['target']사이킷런에서 가져온 load_iris() 함수를 사용하면 바로 데이터를 가지고 올 수 있습니다.
print(iris)를 해 보시면 어떤 구조로 되어 있는지 알 수 있습니다.
가져온 데이터는 "data", "feature_names", "filename", target", "target_names"라는 이름으로 구분된 배열(array) 데이터로 구성되어 있으며 총 150개의 레코드를 가지고 있습니다.
이 중에서 사용할 데이터는 훈련/검증/테스트 용 데이터로 사용할 "data"와 결과가 저장된 "target"입니다.
각 데이터를 x와 y로 할당합시다.
train_x, test_x = x[:120], x[120:]
train_y, test_y = y[:120], y[120:]앞쪽에 있는 120개의 데이터는 훈련용 데이터로 사용하고 나머지 데이터는 테스트용으로 사용하도록 하죠.
[:120]은 처음부터 120번째 데이터까지의 모든 데이터를 의미하고, [120:]은 120번째 데이터에서 뒤쪽의 모든 데이터를 의미합니다.
train_x = np.reshape(train_x, (120, 4, 1))
test_x = np.reshape(test_x, (30, 4, 1))모델에서 사용할 수 있는 형태로 train_x와 test_x의 형태를 재정의합니다.
입력은 4개 Column, 1개 Row씩 사용되며 총 120번을 반복하는 형태입니다.
따라서 1회에 4개 Column, 1개 Row씩 처리하는 형태로 바꿉니다.
그리고 이제 모델을 지정해야죠.
model = keras.Sequential()
model.add(Conv1D(4, 3, activation='relu', input_shape=(4,1)))
model.add(Flatten())
model.add(Dense(10, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(3, activation="softmax"))입력층의 다음은 Conv1D 레이어를 배치합니다.
Conv1D 레이어는 컨볼루션 레이어로 Conv1D, Conv2D, Conv3D 등 몇 종류가 있습니다.
Conv1D는 이름처럼 1차원 배열의 데이터에 사용하고 Conv2D는 2차원 배열의 데이터, 즉 이미지와 같은 데이터에 사용합니다.
여기에서는 Conv1D를 사용하면 되겠죠.
파라미터의 의미는 Conv1D 레이어에서 사용할 커널(=필터)의 수가 4개, 커널의 크기는 3, 활성화 함수는 "relu", 입력의 형태는 (4, 1)이라는 뜻입니다.
Flatten 레이어는 2차원 데이터를 1차원 데이터로 바꾸는 역할을 합니다.
뒤에 따라오는 Dense 레이어에 맞춰주려면 1차원으로 바꿔야겠죠.
앞에서 사용한 Conv1D의 입력형태가 1차원 데이터처럼 보이지만 (4)가 아니라 (4, 1)인 것을 주목하세요.
2차원 데이터입니다.
완전연결층인 Dense 레이어는 각각 10개의 노드(퍼셉트론)를 가지고 있으며 활성화함수는 relu를 사용합니다.
마지막 출력층은 노드가 3개(분류 갯수가 3개죠)인 Dense 레이어를 사용했습니다.
그리고 분류를 위한 모델이므로 마지막 출력층에는 Softmax 함수를 활성화함수로 사용했습니다.
model.compile(optimizer="SGD", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
model.summary()모델의 레이어 배치가 끝났으니 모델을 컴파일 합니다.
Optimizer는 SGD, 손실함수는 sparse_categorical_crossentropy 함수를 선택하고 로그는 accuracy(정확도)를 저장합니다.
model.summary() 함수를 통해서 완성된 모델의 형태를 볼 수 있습니다.
model.fit(train_x, train_y, epochs=1000, verbose=0, batch_size=20)
loss, acc = model.evaluate(test_x, test_y)
result = model.predict(test_x)학습과 검증, 그리고 예측을 하는 것으로 CNN 모델의 사용이 끝났습니다.
이전 글에서 배운 DNN과 그다지 차이가 없죠.
전체코드를 실행해보면 다음과 같은 결과를 얻을 수 있습니다.

잘 동작하는군요.
그런데 마지막의 예측 결과가 주로 2, 가끔 1이 나오고 0은 아예 없네요.
이유는 우리가 읽어들인 iris 데이터가 분류결과가 0, 1, 2의 순서로 정렬되어 있기때문입니다.
정렬된 상테로 앞쪽의 120개를 훈련에 사용하고 뒤쪽의 30개를 테스트에 사용하다보니 학습의 데이터도 편향되어 있고... 실제로 테스트 데이터의 기대 결과는 모두 2입니다.
그럼 예측 결과도 잘못 된 것들이 나오겠지요.
그래서 정확도(accuracy)가 0.8에 그치는 겁니다.
이런 문제를 해결하기 위하여 데이터를 Shuffle, 즉 뒤섞어 줄 수 있습니다
그런데 우리는 데이터를 읽어올때 결과 데이터를 따로 읽어왔기때문에 속성데이터와 결과 데이터가 어긋나게 됩니다.
그럼 데이터를 읽어오는 부분을 고쳐봅시다.
from sklearn.model_selection import train_test_split
iris = load_iris()
x = iris['data']
y = iris['target']
train_x, test_x, train_y, test_y = train_test_split(x, y, stratify=y, test_size=0.2, random_state=30)데이터 배열을 붙이고 섞고.. 하려니 귀찮기때문에 사이킷런의 model_selection 모듈에서 train_test_split 모듈을 가져다 쓰겠습니다.
필요한 라이브러리를 추가로 import 합니다.
그리고 train_x, test_x, train_y, test_y의 값을 train_test_split 함수를 이용해서 섞은 후 훈련데이터와 테스트 데이터로 나누어 가져옵니다.
train_test_split 함수의 파라미터는 다음과 같은 설정을 가지고 있습니다.
- stratify: y로 설정하면 분할된 샘플의 class 갯수를 동일한 비율로 유지함
- test_size: 검증/테스트 셋으로 할당할 비율을 설정함. 기본 값은 0.25 (=25%)
- random_state: 랜덤 수 발생을 위한 시드값
- suffle: 섞기 모드, 기본 값은 True이므로 지정하지 않으면 자동으로 섞어줌
고치기 전의 코드에서는 앞쪽 120개의 데이터를 훈련용, 나머지 30개의 데이터를 테스트/검증용으로 지정했는데 이번에는 그냥 비율로 지정했습니다.
그럼 CNN 모델을 위한 입력 데이터를 재정의 할 때, 그 크기가 바뀌었겠죠.
train_x = np.reshape(train_x, (len(train_x), 4, 1))
test_x = np.reshape(test_x, (len(test_x), 4, 1))이렇게 바꾸어 줍니다.
그럼 수정한 코드를 실행해 봅시다.
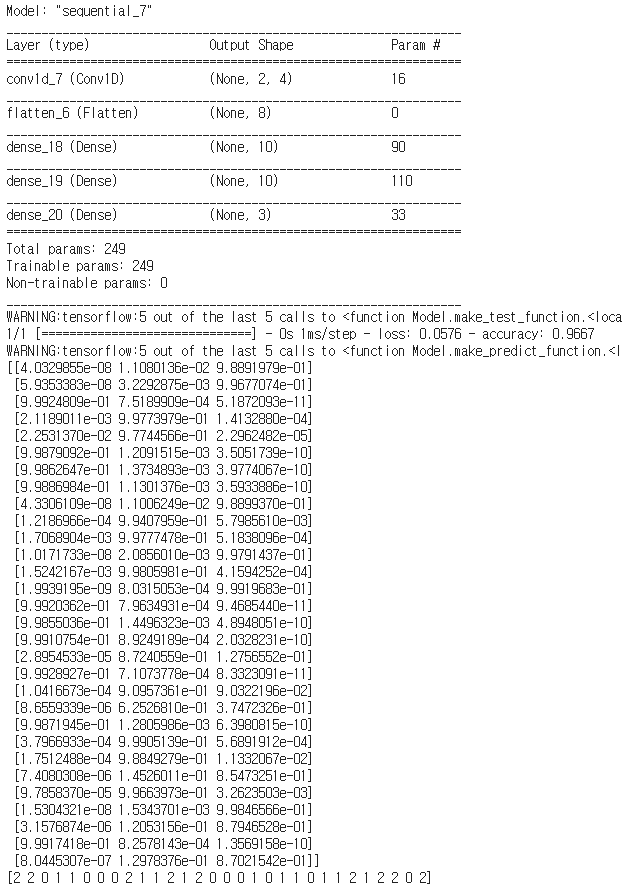
아까와 달리 분류값도 다양하고, 특히 정확도가 0.9667로 거의 1에 가깝습니다.
마지막으로 수정된 전체 코드를 보겠습니다.
import numpy as np
from tensorflow import keras
from tensorflow.keras.layers import Dense, Conv1D, Flatten
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
x = iris['data']
y = iris['target']
train_x, test_x, train_y, test_y = train_test_split(x, y, stratify=y, test_size=0.2, random_state=30)
train_x = np.reshape(train_x, (len(train_x), 4, 1))
test_x = np.reshape(test_x, (len(test_x), 4, 1))
model = keras.Sequential()
model.add(Conv1D(4, 3, activation='relu', input_shape=(4,1)))
model.add(Flatten())
model.add(Dense(10, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(3, activation="softmax"))
model.compile(optimizer="SGD", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
model.summary()
model.fit(train_x, train_y, epochs=1000, verbose=0, batch_size=20)
loss, acc = model.evaluate(test_x, test_y)
result = model.predict(test_x)
print(result)
print(np.argmax(result, axis=1))
이번 글에서는 CNN 모델의 기본 형태를 살펴보았습니다.
그 외의 다른 모델도 거의 동일한 방식을 사용하기때문에 이젠 어떤 모델이라도 문제없이 사용하실 수 있을 것입니다.
단 YOLO는 조금 다릅니다.
YOLO에 대한 예제 코드는 정리가 되는 대로 포스팅 하도록 하겠습니다.
'AI 기반 이론' 카테고리의 다른 글
| 파이썬으로 프로그래밍에 도전하자(1) (0) | 2020.12.06 |
|---|---|
| [AI 실습] AI & 딥러닝 실습 코드 개발 및 공유 (0) | 2020.12.04 |
| 딥러닝 모델 구현코드의 기본형태를 알아보자(with Keras) (0) | 2020.12.01 |
| 구글 Colab을 이용해서 실습을 해 봅시다. (2) | 2020.11.25 |
| 딥러닝 서버 환경 구축(4): 텐서플로우 2.x를 위해서 그냥 virtualenv로.. (0) | 2020.09.15 |