
최근 AI 모델의 경량화를 사업 아이템으로 하여 서비스를 개발하거나 창업을 하는 회사들이 늘고 있습니다.
좋은 사업모델이기도 하지만 한 편으로는 거대 자본을 기반으로 한 공룡 기업에게 지배당하지 않으려는 발버둥으로도 보여서 약간 씁쓸하기도 합니다.
작년(2022년) 11월 30일에 발표된 ChatGPT를 기점으로 많은 초거대 AI 기반의 생성형 AI가 등장하기 시작하였고 전 세계적인 이슈가 되고 있는데 이러한 시대적 흐름에 편승하고자 하는 기업이 늘어나는 것은 당연한 일일 것입니다.
그러나 이름 그대로 초거대 AI를 기반으로 하기 위해서는 상상하기 어려울 정도의 비용이 요구되고 있죠.
ChatGPT를 발표한 OpenAI의 경우도 ChatGPT를 개발하면서 2022년 한 해에 총 5억4천만 달러의 손실을 입었다고 합니다.
지금의 환율을 대충 1달러에 1,330원정도라고 본다면 한화로 약 7,182억원의 손실입니다.
더군다나 향후에 ChatGPT보다 더욱 발전한 스마트한 AI를 개발하기 위하여 1,000억 달러 즉 한화로 약 133조원의 투자금을 유치할 계획이라고 하죠.
OpenAI Reportedly Lost $540 Million Developing ChatGPT in 2022 (yahoo.com)
OpenAI Reportedly Lost $540 Million Developing ChatGPT in 2022
Language models don't come cheap, if the chatbot's costs are any indication
www.yahoo.com
또한 ChatGPT의 1일 운영 비용은 약 10만달러, 약 1억 3,300만원이 소요된다고 하니...
이러한 수치만 보더라도 세계적인 규모의 거대기업이라도 쉽게 덤비지 못하는 상황이라고 볼 수 있습니다.
결국 일반적인 기업이라면 AI 사업을 포기하거나... 글로벌 공룡기업의 서비스를 유료로 사용하면서 그들의 정책에 휘둘리거나...
그렇지 않으면 그들이 신경쓰지 않는 틈새 시장을 발굴할 수 밖에 없는 것이 현실입니다.
그러다보니 글로벌 AI 서비스 업체가 구현하는 기존의 모델이 아닌, 일반적인 중소규모 기업들도 접근할 수 있을 정도의 작은 규모를 가진 경량 AI 모델의 연구, 개발에 투자하게 된 것이라고 볼 수 있습니다.
AI 모델의 경량화 기술은 AI 모델이 학습과 추론 과정에서 요구하는 고비용의 컴퓨팅 자원과 수많은 연산량으로 인해 발생하는 개발 지연, 비용 문제 등을 개선 또는 해결하기 위해서 활용되고 있으며, 2015년 캐나다 토론토 대학교의 제프리 힌튼 교수가 제안한 "Distillation 기법"에서 시작되었다고 합니다.
기술적으로는 AutoML, Pruning(가지치기), Quantization(양자화) 등의 기법을 통해 대용량의 모델이나 다수의 모델을 작은 규모로 압축하고 학습 속도를 높이면서도 그 성능은 유지하는 기술을 말합니다.
Distillation(증류) 기법이란 큰 모델의 지식을 작은 모델로 전달하는 기술이며 이를 통해 작은 모델이 큰 모델과 유사한 성능을 내도록 학습시킬 수 있습니다.
일반적으로, 큰 모델은 작은 모델보다 더 정확하게 예측할 수 있지만, 큰 모델은 작은 모델보다 더 많은 계산 리소스를 필요로 하기 때문에 Distillation 기법을 통해서 개발할 수 있는, 큰 모델의 성능을 유지하는 작은 모델은 사업적으로 많은 가능성을 보여주고 있습니다.
Distillation 기법은 크게 Knowledge Distillation(지식 증류)과 Data Distillation(데이터 증류)으로 구분할 수 있습니다.
Knowledge Distillation은 큰 모델로부터 작은 모델로 지식을 전달하는 과정을 다룹니다.
큰 모델은 작은 모델보다 더 많은 지식 용량을 가지지만 이 용량이 완전히 활용되지 않을 수 있기 때문에 용량의 낭비가 발생할 수 있습니다.
또한 큰 모델을 평가하는 것은 작은 모델을 평가하는 것과 비슷한 계산 비용이 들 수 있습니다.
그런데 Knowledge Distillation은 큰 모델의 지식을 작은 모델로 손실 없이 전달할 수 있으며, 작은 모델은 계산 비용이 적기 때문에 성능이 낮은 하드웨어(예: 모바일 기기)에도 배포할 수 있습니다.
실제로 Knowledge Distillation은 객체 인식, 음성 모델, 자연어 처리 등 다양한 AI 분야에서 성공적으로 적용되었습니다.
Data Distillation은 학습 데이터의 크기를 줄이고 모델의 정확도를 향상시키는 방법입니다.
학습 데이터의 크기를 줄이는 이유는 모델을 더 빠르게 학습시키기 위해서인데 왜냐하면 모델은 전체 데이터를 학습할 필요가 없기 때문입니다.
Data Distillation은 일부 데이터만 사용하여 모델을 학습시킨 후, 배포할 때는 전체 데이터를 학습한 모델과 같은 정확도를 내는 방식입니다.
이렇게 하면 일부 데이터만 학습한 모델은 더 이식성이 높고 다양한 데이터셋에 쉽게 배포할 수 있게 됩니다.
Data Distillation의 기본 아이디어는 전체 데이터를 사용하여 모델을 학습시키는 것이 아니라, 데이터를 사용하여 학습하는 방법을 배우는 것입니다.
이는 전체 데이터가 모든 예제에 관련성이 있는 것이 아니라, 관련성이 없는 데이터를 제거하면 학습이 쉬워지기 때문입니다.
실제로 일부 관련성이 없는 데이터를 제거하면 모델의 정확도가 향상될 수 있기 때문에 Data Distillation은 불필요한 데이터를 제거하여 학습을 쉽게 만드는 과정이라고 할 수 있습니다.
Distillation은 주로 두 가지 방법으로 수행됩니다.
첫 번째 방법은 큰 모델의 예측과 작은 모델의 예측을 비교하여 작은 모델이 큰 모델의 예측을 따르도록 하는 것입니다.
이를 위해 큰 모델의 출력과 작은 모델의 출력 간의 손실을 최소화하는 것이 일반적인 방법입니다.
두 번째 방법은 큰 모델이 만든 Softmax 출력을 작은 모델의 입력으로 사용하여 작은 모델을 학습시키는 방법이며, 이 방법은 작은 모델이 큰 모델이 예측한 확률 분포를 학습할 수 있도록 합니다.
이러한 AI 모델의 경량화 기법을 적용함으로써 중소기업이라도 AI 산업에 적극적으로 동참할 수 있는 기회를 잡을 수 있다고 생각됩니다.
그러면 이번에는 제가 작업하고 있는 AiDAOps와 같은 AutoML 관련 시스템은 어떻게 활용할 수 있을지도 궁금해지는데요..
지금과 같은 추세에서 AutoML 계열의 시스템이 도움이 될 수 있을까.. 라는 걱정이 되기도 합니다.
그런데 앞에서 AI 모델의 경량화 기법에 사용되는 세부 기법 중에 AutoML도 포함되어 있었습니다.
AutoML은 이러한 AI 모델의 경량화에 어떻게 적용될 수 있을까요?
AutoML이 대용량의 모델이나 다수의 모델을 작은 규모로 압축하고 학습 속도를 높이면서도 그 성능은 유지하기 위해 활용되는 방식은 AMC: AutoML for Model Compression and Acceleration on Mobile Devices라는 논문에서 찾아볼 수 있습니다.
[1802.03494] AMC: AutoML for Model Compression and Acceleration on Mobile Devices (arxiv.org)
AMC: AutoML for Model Compression and Acceleration on Mobile Devices
Model compression is a critical technique to efficiently deploy neural network models on mobile devices which have limited computation resources and tight power budgets. Conventional model compression techniques rely on hand-crafted heuristics and rule-bas
arxiv.org
AMC는 강화학습을 사용하여 모델의 채널을 자동으로 잘라내는 전략을 제공합니다.
예전에 많이 사용되었던 모델 압축 기법은 수작업으로 휴리스틱과 규칙을 결정하고 각 도메인의 전문가가 모델의 크기, 속도, 정확도 간의 절충점(Trade-Off)을 탐색하는데, 이는 비효율적이고 시간이 많이 걸립니다.
그래서 AMC는 학습 기반의 압축 전략을 사용하여 기존의 규칙 기반의 압축 전략보다 더 높은 압축 비율과 정확도를 달성하고 인간의 노력을 절약할 수 있도록 하기위한 비법을 제안하고 있습니다.
이렇게 모델을 압축함으로써 AMC는 MobileNet과 같은 모바일 기기에도 적용할 수 있는 AI 모델을 구성할 수 있습니다.
MobileNet을 AMC로 압축하는 과정은 다음과 같습니다.
먼저 강화학습 에이전트를 사용하여 FLOPs 제약 조건 하에서 최적의 채널 수를 탐색하고, 탐색된 채널의 수에 따라 모델의 가중치를 잘라냅니다.
그리고 잘라낸 가중치로부터 모델을 미세 조정함으로써 모델의 압축을 완료하는 것입니다.
AMC로 압축한 MobileNet은 ImageNet 데이터셋에서 0.1%의 정확도 손실만으로 1.81배의 안드로이드 폰에서의 추론 속도 향상과 1.43배의 Titan XP GPU에서의 추론 속도 향상을 달성했다고 합니다.
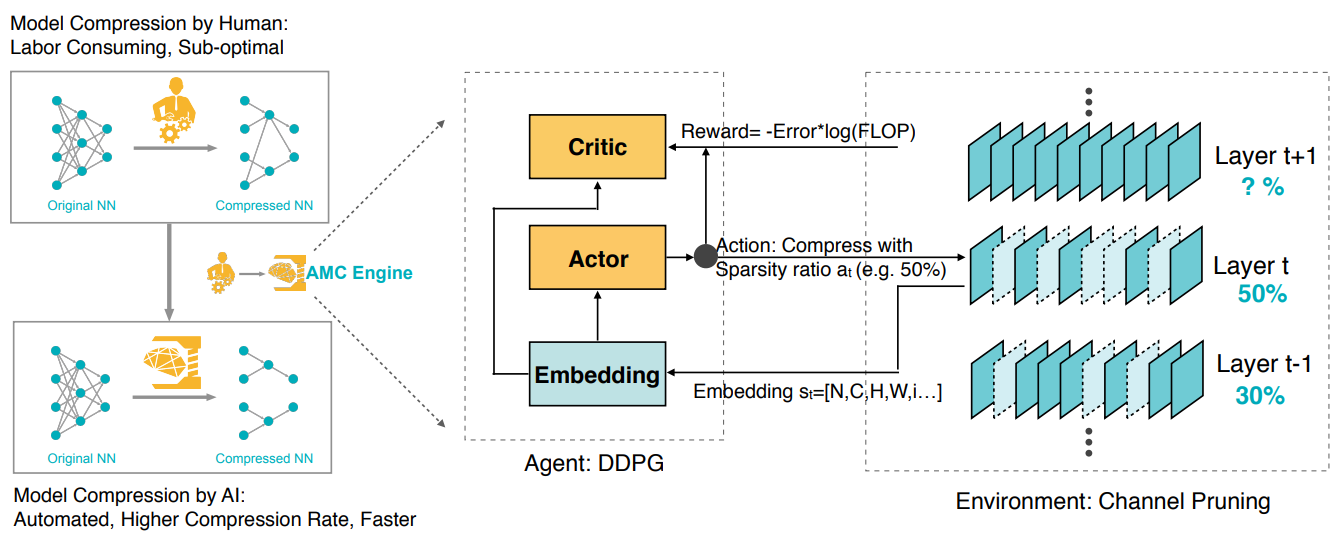
그럼 이러한 AMC와 같은 기술에 AiDAOps에는 어떻게 적용될 수 있을까...
여러 가지의 방법이 있겠지만 가장 간단한 방법은 AiDAOps가 기본으로 제공하는 모델에 이러한 경량화 모델을 지원하거나.. 아니면 이런 경량화 모델을 만들 수 있도록 지원할 수 있으면 되지 않을까? 하고 생각해 볼 수 있습니다.
아직 AiDAOps는 개발의 극 초반에 해당하기 때문에 앞으로 가야할 길이 멉니다만 다양한 개발 방향과 활용 방안을 미리 생각해 볼 수 있다는 것은 좋은 기회라고 보고 있습니다.
'AiDALab Project > AiDAOps' 카테고리의 다른 글
| 작업 계획을 위한 관련 정보의 사전조사를 LLM으로 하면 편하겠다 (2) | 2024.01.24 |
|---|---|
| DevOps와 MLOps (2) | 2023.12.10 |
| FastAPI에서의 라우팅 (0) | 2023.04.21 |
| FastAPI를 기반으로 데이터 파일 전송 및 읽기 (0) | 2023.04.21 |
| 서버 환경 설치 및 설정 (0) | 2023.04.21 |