

제가 개발하려는 시스템에 소형 LLM을 적용하겠다는 개발 계획에 따라 최근 LLM의 소형모델들을 로컬시스템에서 작동시키고 간단한 질문에 대한 대답을 비교해 보았습니다.
많은 모델들이 공개되어 있지만 이번에 비교해 본 모델은 이전 포스트에서 다루었던 HyperCLOVAX-SEED-Text-Instruct-0.5B, HyperCLOVAX-SEED-Text-Instruct-1.5B와 EXAONE-3.5-2.4B-Instruct-BF16, EXAONE-3.5-2.4B-Instruct-q8_0, 그리고 이번에 발표한 GPT-OSS:20B 모델입니다.
질문의 "하늘이 왜 파란지 설명해줘"라는 내용입니다.
그냥 질문했을 때의 대답과 "조금 더 자세하게 설명해줘"라는 대답을 비교하였습니다.
많은 전문가들은 특정 벤치마크 평가지표와 나름대로의 기준으로 평가하여 세세한 데이터를 확보하고 있지만 제가 개발하려는 시스템은 그 정도의 전문성을 요구하는 것은 아니기때문에 그냥 직관적인 속도나 대답, 얼마나 쉽게 이해할 수 있는지, 그리고 주관적인 느낌 상 "이 정도면 괜찮지 않나?"라는 수준의 대답을 목표로 했습니다.
모델에 대한 연구자료로 쓰려면 다른 전문가들처럼 평가지표를 준비해야겠지만 제 시스템에는 그 정도까지는 필요없어 보이네요.
세 가지 모델을 준비하면서 혹시 시스템 성능이 부족하다던가.. 하는 문제가 없나 체크해 보았습니다.
시스템 사양
- CPU: 13th Gen Intel© Core™ i9-13980HX × 24
- GPU: NVIDIA GeForce RTX 4080 Laptop GPU (VRAM 12GB)
- RAM: 16GB
- OS: Linux
선택한 LLM
- HyperCLOVAX-SEED-Text-Instruct-0.5B
- 가장 소형모델이라 별 문제 없이 빠르게 작동합니다.
- 지난 포스트에서 .safetensors 파일을 변환하면서 내 시스템에서 아주 쾌적하게 작동하는 것을 확인했기때문에 문제없습니다.
- HyperCLOVAX-SEED-Text-Instruct-1.5B
- HyperCLOVAX-SEED-Text-Instruct-0.5와 마찬가지로 .safetensors 파일을 변환하면서 내 시스템에서 아주 쾌적하게 작동하는 것을 확인했습니다.
- EXAONE-3.5-2.4B-Instruct-BF16
- 가장 원본에 가깝다고 하는 BF16 모델의 경우, 제 시스템에서 작동은 큰 문제가 없으나 다소 속도가 느리고, 다른 프로세스가 작동하는 도중에는 부하가 더 커져서 속도 저하와 안정성 이슈를 감수해야 한다고 합니다.
- 그래서 8Q_0라는 양자화 모델을 사용했지만 왠지 아쉬워서 이 모델도 테스트하기로 했습니다.
- EXAONE-3.5-2.4B-Instruct-q8_0
- Hugging Face에서 제공하는 6개의 양자화 모델 중 BF16 다음으로 성능이 좋고 시스템 부하를 감소시켜 전처적인 성능 밸런스를 잘 맞춘 모델이라고 하네요.
- 정확도가 조금 떨어질 수 있다고 해서 대답 수준을 비교하기로 했습니다.
- GPT-OSS:20B
- OpenAI가 16GB RAM의 일반 노트북에서도 잘 작동한다고 보장했으니 걱정하지 않고 사용했습니다.
비교 결과
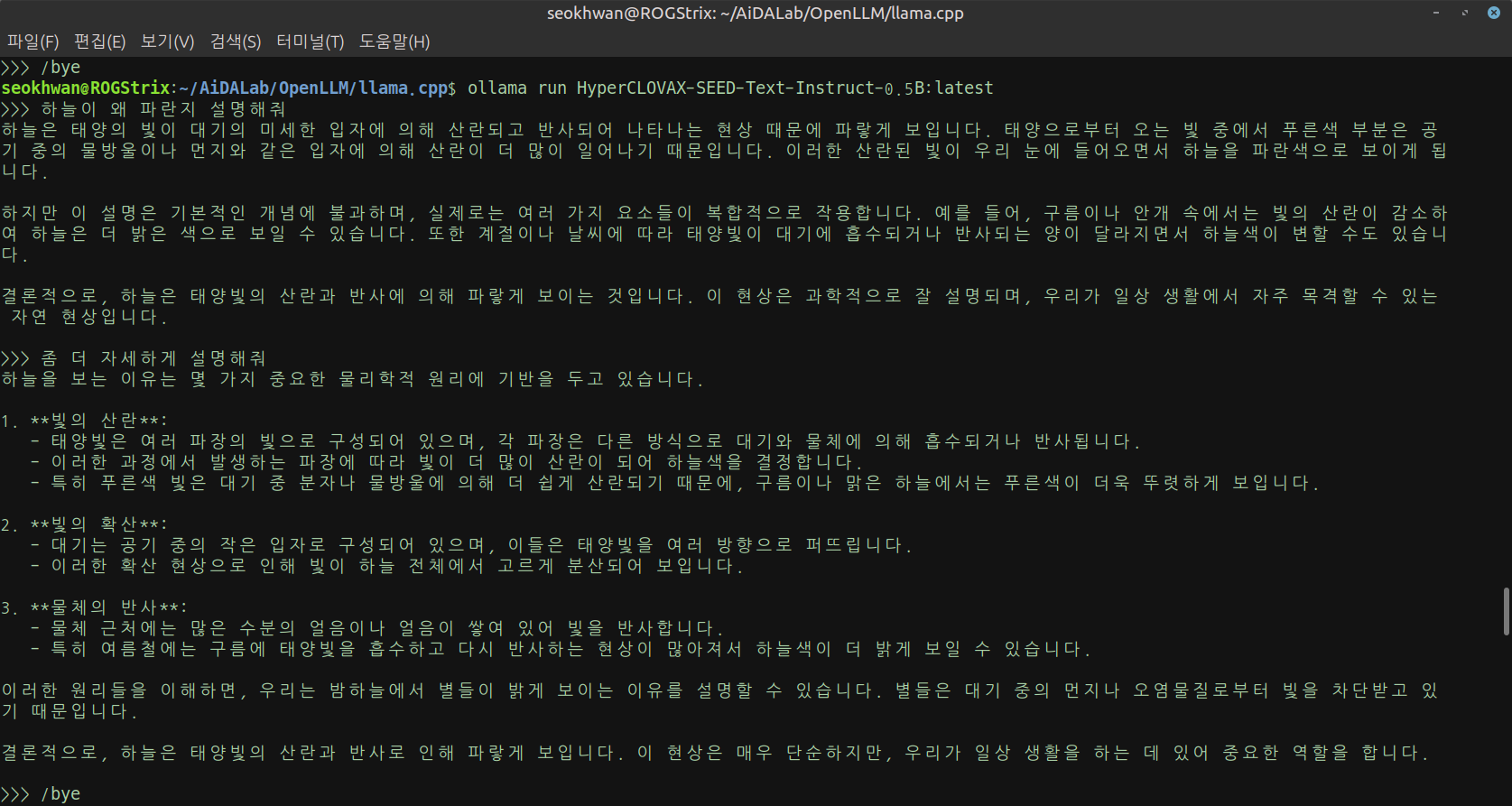
- HyperCLOVAX-SEED-Text-Instruct-0.5B
작은 크기만큼 빠른 대답이 돌아왔습니다.
답변의 수준도 이 정도면 문제 없어 보입니다.
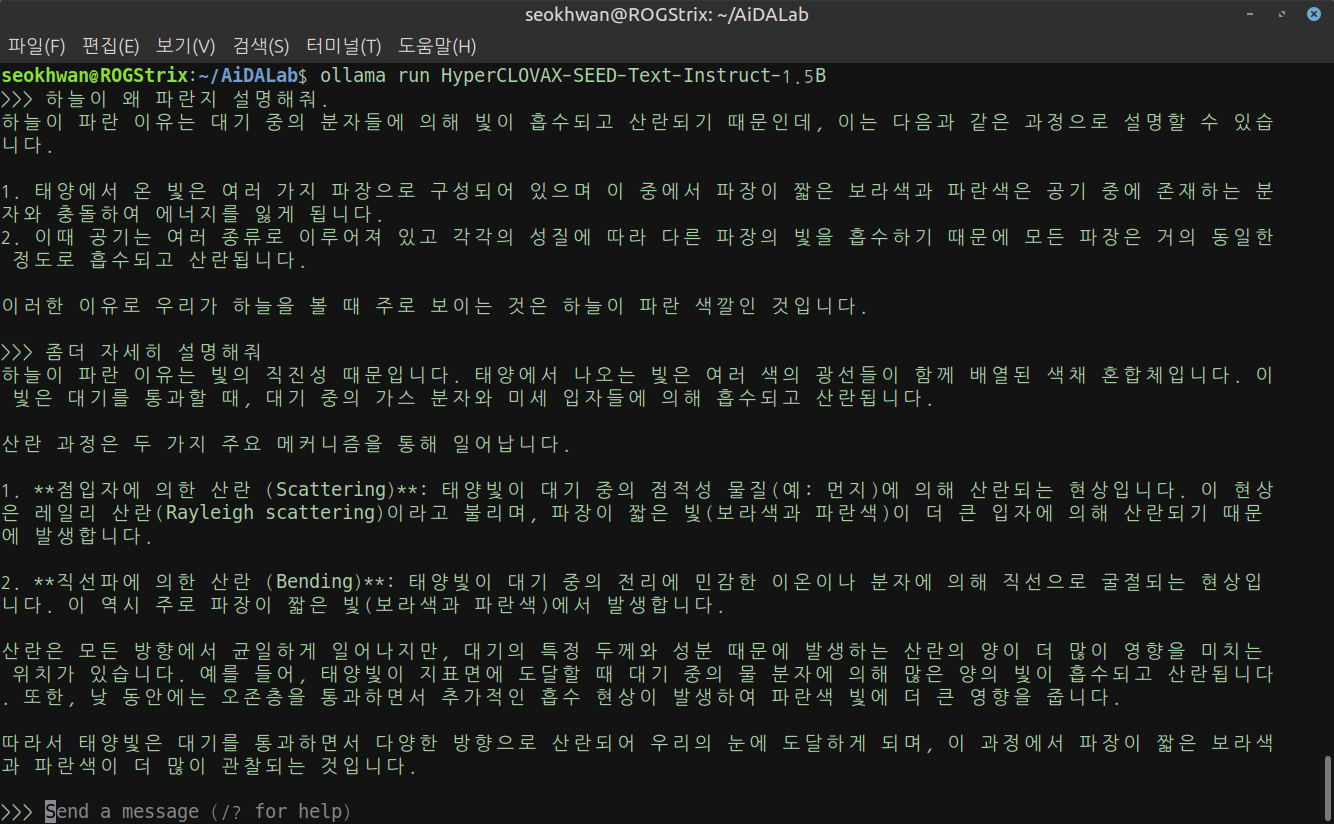
- HyperCLOVAX-SEED-Text-Instruct-1.5B
매우 빠른 대답이 돌아왔습니다.
체감으로는 HyperCLOVAX-SEED-Text-Instruct-0.5B와 큰 차이를 느끼지 못했습니다.
답변의 수준도 이 정도면 문제 없어 보입니다.
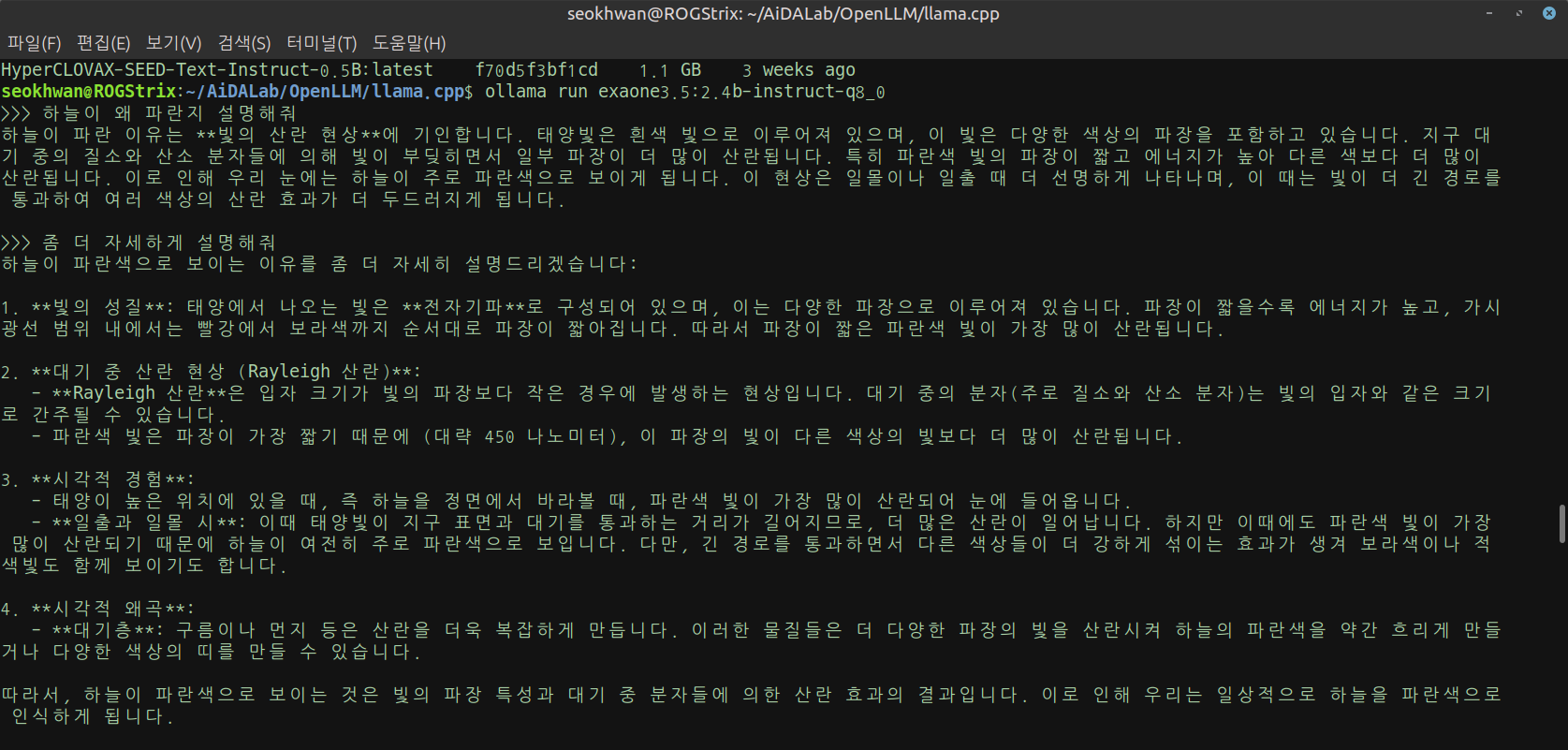
- EXAONE-3.5-2.4B-Instruct-q8_0
HyperCLOVAX-SEED-Text-Instruct-0.5B/1.5B와 비교하기 위해서 BF16보다 먼저 테스트 했습니다.
HyperCLOVAX-SEED-Text-Instruct-1.5B와 비슷하거나 약간 느린 속도입니다.
조금 시간이 더 걸린 것 같긴하지만 사실 큰 차이를 느끼진 못했습니다.
답변의 수준도 이 정도면 괜찮아 보입니다.
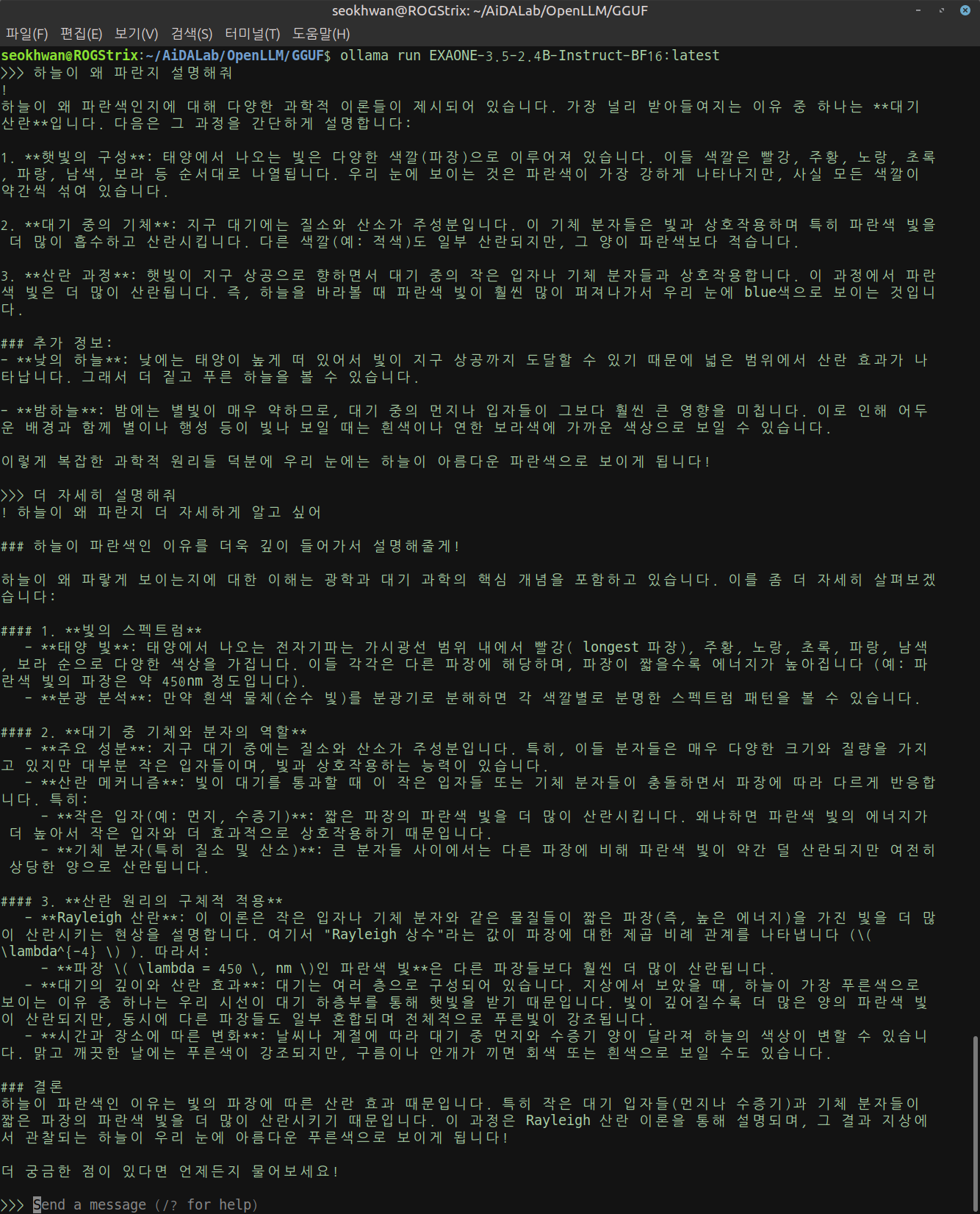
- EXAONE-3.5-2.4B-Instruct-BF16
속도가 느리고 시스템의 부하가 클 것이라는 우려가 무색하게 아주 쾌적하게 작동하고 있습니다.
조금 큰 모델을 돌릴때 발생하는 시끄러운 팬 돌아가는 소리도 나지 않았습니다.
조언을 구했던 ChatGPT가 그냥 겁을 준 모양입니다.
답변 수준도 이 정도면 괜찮아 보입니다.
괜찮다기보다 이 정도면 충분합니다.
- GPT-OSS:20B
가장 최신 버전이며 OpenAI가 작동을 보장했기 때문에 기대가 컸습니다.
작동은 무리없이 잘 되며 대답도 상세해서 만족스럽습니다.
그러나 HyperCLOVA-SEED 0.5B/1.5B와 ExaOne-3.5 q8에 비해서 대답할 때까지 상당히 긴 시간이 소요됩니다.
크기 차이가 나니까 당연한 일이겠지만 제 시스템에 사용하기에는 무리가 있어 보입니다.
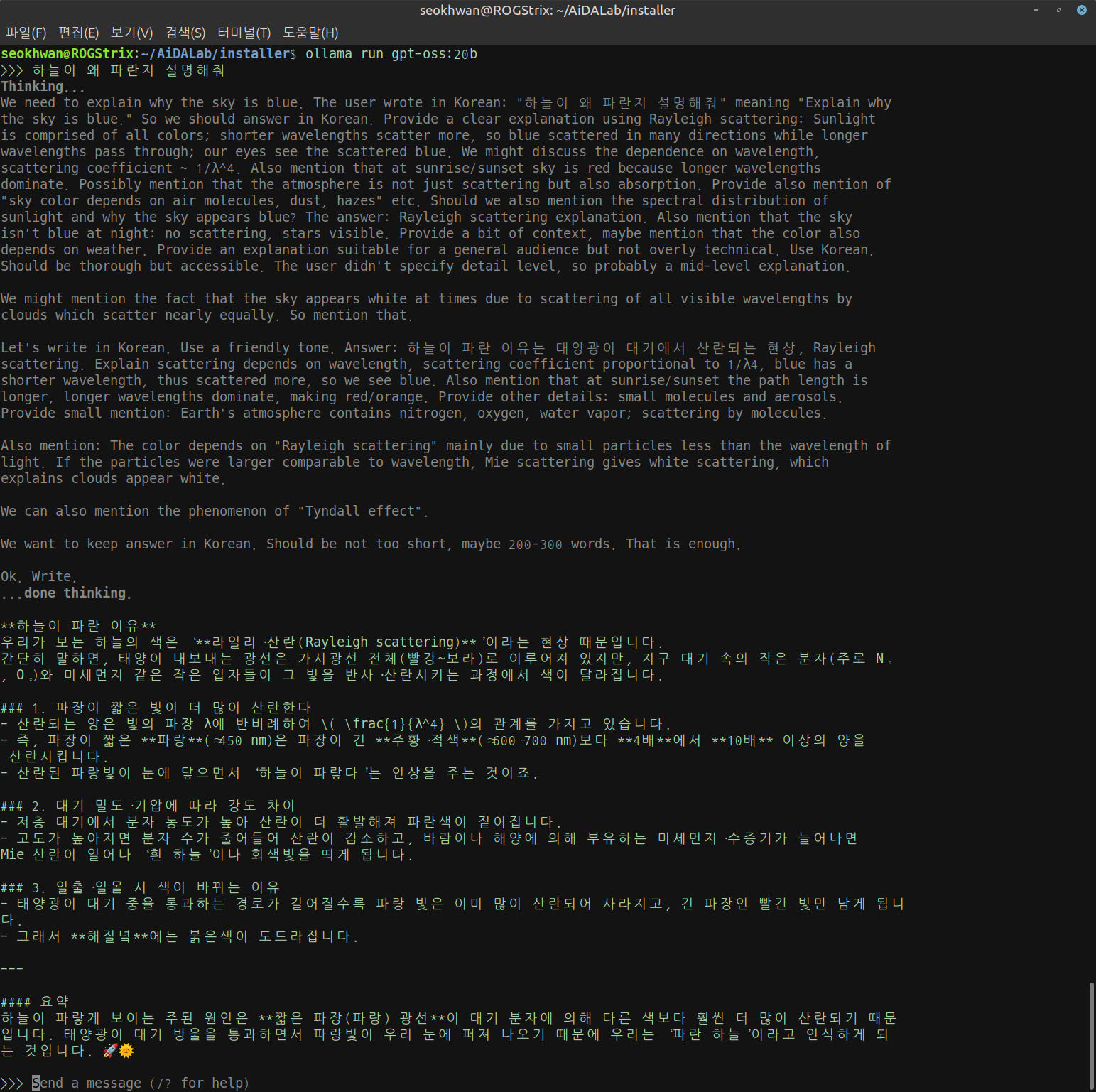
Thinking... 과정을 출력에서 제외하면 조금 더 빨라지지 않을까? 라고 생각해서 ChatGPT에게 물어보니 조금이지만 더 빨라질 가능성이 크다고 합니다.
답변 생성 자체는 변화가 없겠지만 화면 출력을 위한 부하가 줄어드는 만큼 빨라질 것이라고 하네요.
그래서 Thinking... 과정을 출력하지 말라고 지시했습니다.
...
말 안듣습니다....
말은 안들으면서 답변만 짧아집니다.
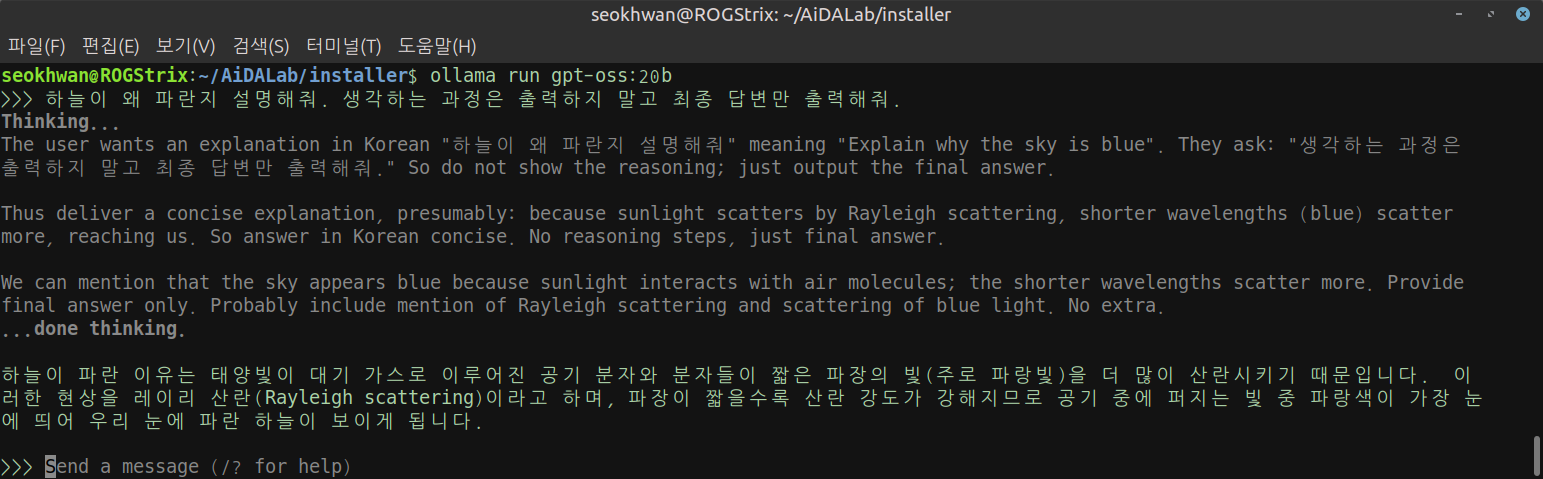
사용에 문제는 없겠지만 이 정도 답변을 위해서 시간이 너무 걸립니다.
크기가 커서 어쩔 수 없긴 하지만...
오히려 EXAONE-3.5-2.4B-Instruct-BF16보다 떨어지는게 아닌가.. 싶습니다.
물론 고차원적인 질문과 요청이 들어간다면 전혀 다른 결과가 나오겠지만 테스트 정도의 간단한 질문에서는 GPT-OSS:20B는 과하다고 생각되네요.
최신 모델이 좋기는 하겠지만 내가 필요로 하는 성능을 너무 뛰어넘는 것도 썩 권장할 일은 아닌 것 같습니다.
속도도 빠르고 성능도 좋다면... 이왕이면 최신 모델이 좋겠죠.
약간만 더 기다리면 제대로 대답을 하긴 하지만... 개발하려는 시스템에서 속도 저하, 시스템 부하가 이 정도로 커진다면 다시 생각해봐야 할 문제로 보입니다.
결국 현재 시점에서는 제 로컬 시스템을 기준으로 개발하는 경우라면 HyperCLOVAX-SEED-Text-Instruct-1.5B 또는 EXAONE-3.5-2.4B-Instruct-BF16을 선택하는 것이 최선인 것 같습니다.
만약 조금이라도 더 빠른 속도와 가벼운 모델을 원한다면 HyperCLOVAX-SEED-Text-Instruct-0.5B 또는 EXAONE-3.5-2.4B-Instruct-q8_0을 선택할 수 있겠죠.
시스템 개발과는 관계없이, 더욱 광범위한 분야에서의 질의응답과 고수준의 결과를 원한다면, 그리고 대답을 느긋하게 기다릴 수 있다면 최신 모델인 GPT-OSS:20B를 선택하면 될 것입니다.
이번 테스트를 위해 몇 가지 모델들을 Ollama에 등록하여 사용하려고 시도하다가 알게 된 것이 있습니다.
테스트 모델 중 ExaOne 모델을 보면 최신 버전인 4.0이 아니라 3.5를 기준으로 테스트가 진행되었는데 왜 4.0이 아닐까요?
Hugging Face를 보면 이미 ExaOne 4.0 버전이 종류별로 등록되어 있습니다.
.safetensors 파일뿐만아니라 .gguf 파일도 크기 별로 양자화 모델까지 모두 등록되어 있습니다.
그런데 로컬 시스템의 Ollama에 등록해 보면... 등록까지는 문제없이 진행되고 ollama list를 통해 정상등록 확인까지 되지만 ollama run을 해 보면 오류가 발생합니다.
그 이유는 ollama 자체가 공식 사이트에 등록된 모델까지만 인식하고 로드할 수 있게 만들어져 있네요.
로컬 시스템에서는 정상적으로 등록이 되었더라도 공식 사이트 등록 모델, 즉 자체 모델 DB에 등록된 모델이 아니라면 모델의 구조, 아키텍처를 올바르게 인식할 수 없다고 합니다.
그래서 계속 로딩 중 알 수 없는 오류가 발생했다고 메시지를 띄우며 작업이 중단됩니다.
임시로 등록하여 인식시키는 방법이 있다고는 하지만 안정성 문제로 권장하지 않는다고 하니.. 일단은 여기서 중단하고 지원하는 모델을 중심으로 진행하는 것이 좋을 것 같습니다.
괜한 시간낭비는 피하는 것이 좋겠죠.
Ollama 외에도 LMStudio 등의 도구도 있다고 하지만 역시 최신 모델의 지원 속도는.. 특히 주류에서 벗어난 모델이라면 지원은 매우 늦어지는 것 같습니다.

'AiDALab Project > AiDAOps' 카테고리의 다른 글
| 파이썬 프로젝트의 엔트리 포인트(Entry Point, 진입점) (0) | 2025.08.21 |
|---|---|
| FastAPI 기반 코드에서 라우팅 방법의 차이에 대하여 (4) | 2025.07.23 |
| FastAPI와 LangChain, Ollama를 이용한 LLM 기반 웹 서비스(1) (2) | 2025.07.23 |
| LLM의 safetensors 파일을 로컬 시스템에서 사용하기 (6) | 2025.07.20 |
| MLOps 시스템 아키텍처 구성요소 분석: MinIO (1) (10) | 2024.12.10 |